yipeiwu_com6年前
本文实例讲述了Python3实现爬虫爬取赶集网列表功能。分享给大家供大家参考,具体如下: python3爬虫之爬取赶集网列表。这几天一直在学习使用python3爬取数据,今天记录一下,代...
yipeiwu_com6年前
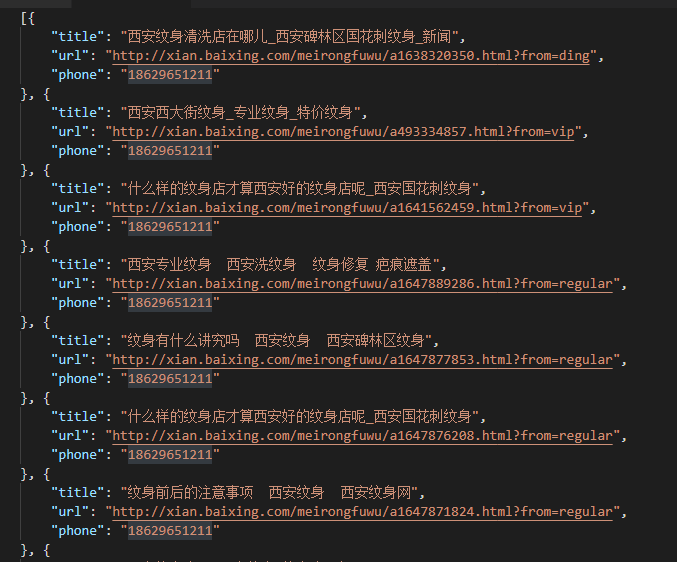
本文实例讲述了Python3爬虫爬取百姓网列表并保存为json功能。分享给大家供大家参考,具体如下: python3爬虫之爬取百姓网列表并保存为json文件。这几天一直在学习使用pyth...
yipeiwu_com6年前
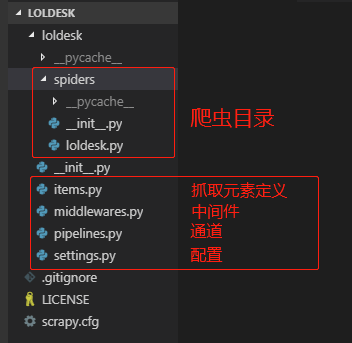
本文实例讲述了Python3爬虫爬取英雄联盟高清桌面壁纸功能。分享给大家供大家参考,具体如下: 使用Scrapy爬虫抓取英雄联盟高清桌面壁纸 源码地址:https://github.co...
yipeiwu_com6年前
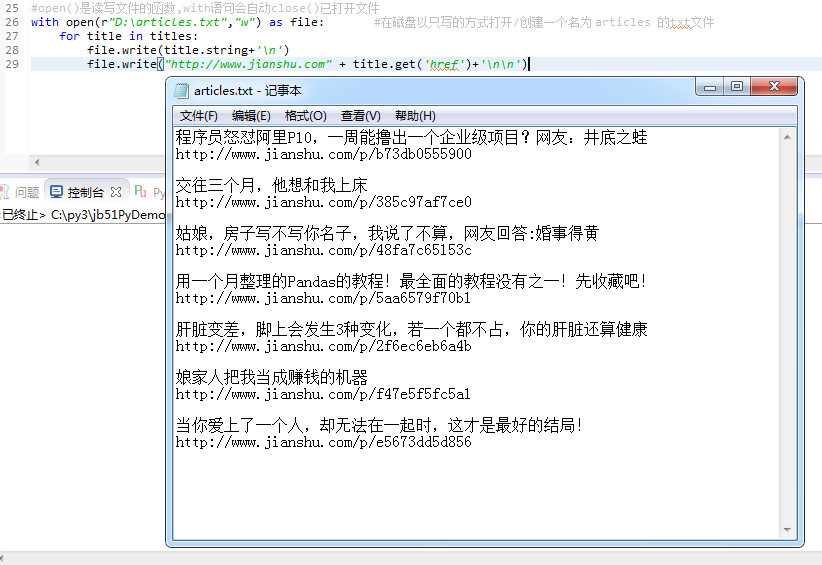
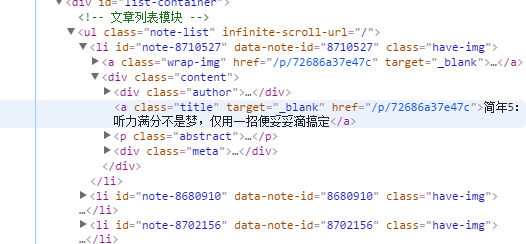
本文实例讲述了Python3实现爬取简书首页文章标题和文章链接的方法。分享给大家供大家参考,具体如下: from urllib import request from bs4 imp...
yipeiwu_com6年前
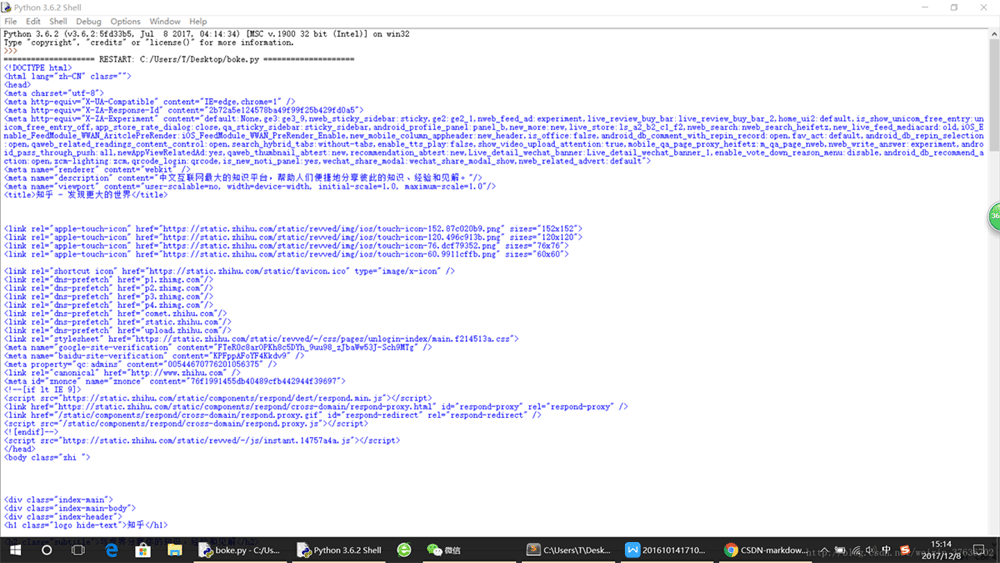
本文实例讲述了Python3爬虫相关入门知识。分享给大家供大家参考,具体如下: 在网上看到大多数爬虫教程都是Python2的,但Python3才是未来的趋势,许多初学者看了Python2...
yipeiwu_com6年前
本文实例讲述了Python3爬虫学习之应对网站反爬虫机制的方法。分享给大家供大家参考,具体如下: 如何应对网站的反爬虫机制 在访问某些网站的时候,网站通常会用判断访问是否带有头文件来鉴别...
yipeiwu_com6年前
本文实例讲述了Python3爬虫学习之爬虫利器Beautiful Soup用法。分享给大家供大家参考,具体如下: 爬虫利器Beautiful Soup 前面一篇说到通过urllib.re...
yipeiwu_com6年前
本文实例讲述了Python3爬虫学习之将爬取的信息保存到本地的方法。分享给大家供大家参考,具体如下: 将爬取的信息存储到本地 之前我们都是将爬取的数据直接打印到了控制台上,这样显然不利于...
yipeiwu_com6年前
本文实例讲述了Python3爬虫学习之MySQL数据库存储爬取的信息。分享给大家供大家参考,具体如下: 数据库存储爬取的信息(MySQL) 爬取到的数据为了更好地进行分析利用,而之前将爬...
yipeiwu_com6年前
自己在刚学习python时写的,中途遇到很多问题,查了很多资料,下面就是我爬取租房信息的代码: 链家的房租网站 两个导入的包 1.requests 用来过去网页内容 2.Beaut...