Python3实现爬取简书首页文章标题和文章链接的方法【测试可用】
本文实例讲述了Python3实现爬取简书首页文章标题和文章链接的方法。分享给大家供大家参考,具体如下:
from urllib import request
from bs4 import BeautifulSoup #Beautiful Soup是一个可以从HTML或XML文件中提取结构化数据的Python库
#构造头文件,模拟浏览器访问
url="http://www.jianshu.com"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
page = request.Request(url,headers=headers)
page_info = request.urlopen(page).read().decode('utf-8')#打开Url,获取HttpResponse返回对象并读取其ResposneBody
# 将获取到的内容转换成BeautifulSoup格式,并将html.parser作为解析器
soup = BeautifulSoup(page_info, 'html.parser')
# 以格式化的形式打印html
#print(soup.prettify())
titles = soup.find_all('a', 'title')# 查找所有a标签中class='title'的语句
'''''
# 打印查找到的每一个a标签的string和文章链接
for title in titles:
print(title.string)
print("http://www.jianshu.com" + title.get('href'))
'''
#open()是读写文件的函数,with语句会自动close()已打开文件
with open(r"D:\articles.txt","w") as file: #在磁盘以只写的方式打开/创建一个名为 articles 的txt文件
for title in titles:
file.write(title.string+'\n')
file.write("http://www.jianshu.com" + title.get('href')+'\n\n')
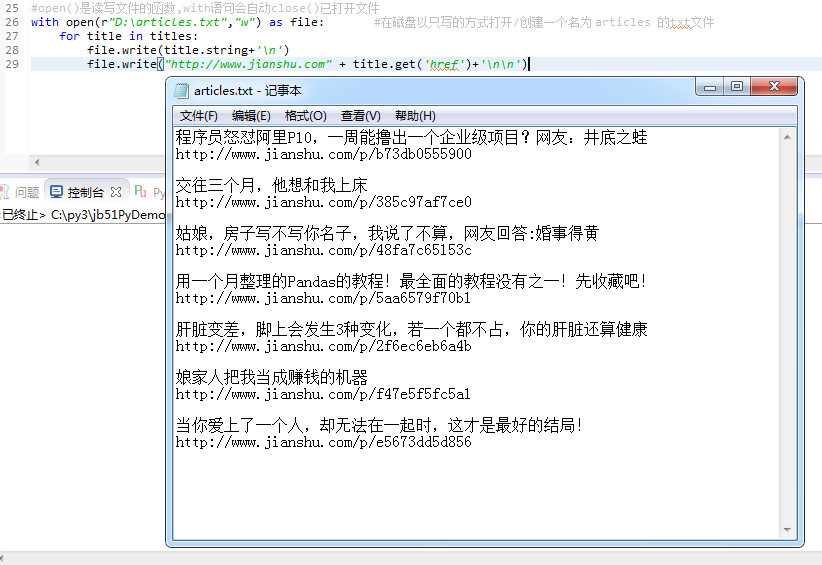
本机测试运行结果如下:
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。