Python3爬虫学习之爬虫利器Beautiful Soup用法分析
本文实例讲述了Python3爬虫学习之爬虫利器Beautiful Soup用法。分享给大家供大家参考,具体如下:
爬虫利器Beautiful Soup
前面一篇说到通过urllib.request模块可以将网页当作本地文件来读取,那么获得网页的html代码后,自然就是要将我们所需要的部分从杂乱的html代码中分离出来。既然要做数据的查找和提取,当然我们首先想到的应该是正则表达式的方式,而正则表达式书写的复杂我想大家都有体会,而且Python中的正则表达式和其他语言中的并没有太大区别,也就不赘述了,所以现在介绍Python中一种比较友好且易用的数据提取方式——Beautiful Soup
Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.
文档中的例子其实说的已经比较清楚了,那下面就以爬取简书首页文章的标题一段代码来演示一下:
先来看简书首页的源代码:
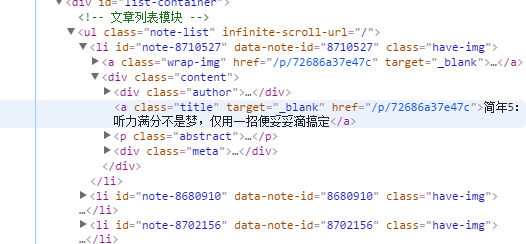
可以发现简书首页文章的标题都是在<a/>标签中,并且class='title',所以,通过
find_all('a', 'title')
便可获得所有的文章标题,具体实现代码及结果如下:
# -*- coding:utf-8 -*-
from urllib import request
from bs4 import BeautifulSoup
url = r'http://www.jianshu.com'
# 模拟真实浏览器进行访问
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
page = request.Request(url, headers=headers)
page_info = request.urlopen(page).read()
page_info = page_info.decode('utf-8')
# 将获取到的内容转换成BeautifulSoup格式,并将html.parser作为解析器
soup = BeautifulSoup(page_info, 'html.parser')
# 以格式化的形式打印html
# print(soup.prettify())
titles = soup.find_all('a', 'title') # 查找所有a标签中class='title'的语句
# 打印查找到的每一个a标签的string
for title in titles:
print(title.string)

PS:关于解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,下表列出了主要的解析器,以及它们的优缺点:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") | (1)Python的内置标准库 (2)执行速度适中 (3)文档容错能力强 |
Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") | (1)速度快 (2)文档容错能力强 |
需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, ["lxml", "xml"]) OR BeautifulSoup(markup, "xml") | (1)速度快 (2)唯一支持XML的解析器 |
需要安装C语言库 |
| html5lib | BeautifulSoup(markup, "html5lib") | (1)最好的容错性 (2)以浏览器的方式解析文档 (3)生成HTML5格式的文档 |
(1)速度慢 (2)不依赖外部扩展 |
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。