Python3爬虫爬取英雄联盟高清桌面壁纸功能示例【基于Scrapy框架】
本文实例讲述了Python3爬虫爬取英雄联盟高清桌面壁纸功能。分享给大家供大家参考,具体如下:
使用Scrapy爬虫抓取英雄联盟高清桌面壁纸
源码地址:https://github.com/snowyme/loldesk
开始项目前需要安装python3和Scrapy,不会的自行百度,这里就不具体介绍了
首先,创建项目
scrapy startproject loldesk
生成项目的目录结构
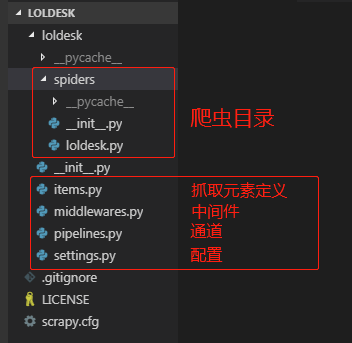
首先需要定义抓取元素,在item.py中,我们这个项目用到了图片名和链接
import scrapy class LoldeskItem(scrapy.Item): name = scrapy.Field() ImgUrl = scrapy.Field() pass
接下来在爬虫目录创建爬虫文件,并编写主要代码,loldesk.py
import scrapy
from loldesk.items import LoldeskItem
class loldeskpiderSpider(scrapy.Spider):
name = "loldesk"
allowed_domains = ["www.win4000.com"]
# 抓取链接
start_urls = [
'http://www.win4000.com/zt/lol.html'
]
def parse(self, response):
list = response.css(".Left_bar ul li")
for img in list:
imgurl = img.css("a::attr(href)").extract_first()
imgurl2 = str(imgurl)
next_url = response.css(".next::attr(href)").extract_first()
if next_url is not None:
# 下一页
yield response.follow(next_url, callback=self.parse)
yield scrapy.Request(imgurl2, callback=self.content)
def content(self, response):
item = LoldeskItem()
item['name'] = response.css(".pic-large::attr(title)").extract_first()
item['ImgUrl'] = response.css(".pic-large::attr(src)").extract()
yield item
# 判断页码
next_url = response.css(".pic-next-img a::attr(href)").extract_first()
allnum = response.css(".ptitle em::text").extract_first()
thisnum = next_url[-6:-5]
if int(allnum) > int(thisnum):
# 下一页
yield response.follow(next_url, callback=self.content)
图片的链接和名称已经获取到了,接下来需要使用图片通道下载图片并保存到本地,pipelines.py:
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
from scrapy.http import Request
import re
class MyImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['ImgUrl']:
yield Request(image_url,meta={'item':item['name']})
def file_path(self, request, response=None, info=None):
name = request.meta['item']
name = re.sub(r'[?\\*|“<>:/()0123456789]', '', name)
image_guid = request.url.split('/')[-1]
filename = u'full/{0}/{1}'.format(name, image_guid)
return filename
def item_completed(self, results, item, info):
image_path = [x['path'] for ok, x in results if ok]
if not image_path:
raise DropItem('Item contains no images')
item['image_paths'] = image_path
return item
最后在settings.py中设置存储目录并开启通道:
# 设置图片存储路径
IMAGES_STORE = 'F:/python/loldesk'
#启动pipeline中间件
ITEM_PIPELINES = {
'loldesk.pipelines.MyImagesPipeline': 300,
}
在根目录下运行程序:
scrapy crawl loldesk
大功告成!!!一共抓取到128个文件夹
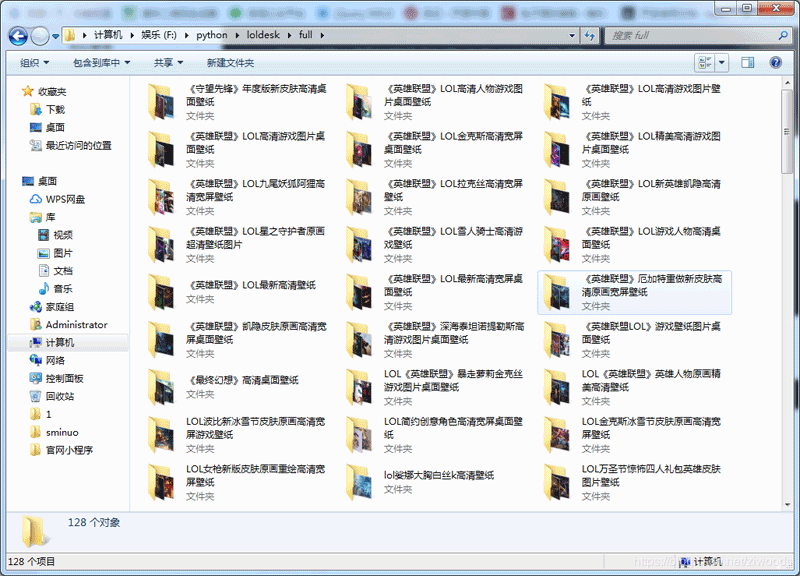
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。