Python3爬虫学习之应对网站反爬虫机制的方法分析
本文实例讲述了Python3爬虫学习之应对网站反爬虫机制的方法。分享给大家供大家参考,具体如下:
如何应对网站的反爬虫机制
在访问某些网站的时候,网站通常会用判断访问是否带有头文件来鉴别该访问是否为爬虫,用来作为反爬取的一种策略。
例如打开搜狐首页,先来看一下Chrome的头信息(F12打开开发者模式)如下:
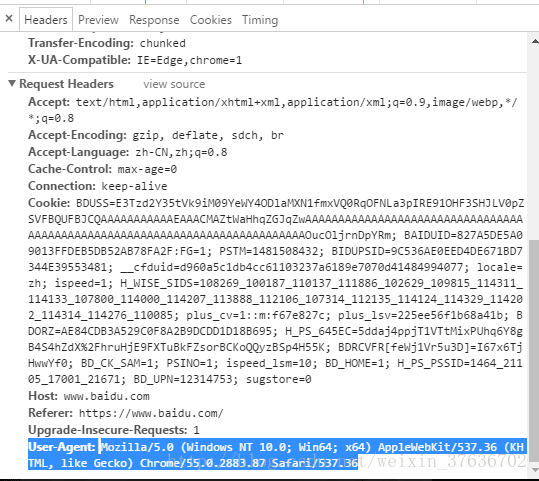
如图,访问头信息中显示了浏览器以及系统的信息(headers所含信息众多,具体可自行查询)
Python中urllib中的request模块提供了模拟浏览器访问的功能,代码如下:
from urllib import request
url = 'http://www.baidu.com'
# page = request.Request(url)
# page.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36')
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
page = request.Request(url, headers=headers)
page_info = request.urlopen(page).read().decode('utf-8')
print(page_info)
可以通过add_header(key, value) 或者直接以参数的形式和URL一起请求访问,
urllib.request.Request()
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
其中headers是一个字典,通过这种方式可以将爬虫模拟成浏览器对网站进行访问。
https://docs.python.org/3/library/urllib.request.html?highlight=request
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。