yipeiwu_com6年前
如下所示: 1.pip install requests 2.pip install lxml 3.pip install xlsxwriter import requests #想...
yipeiwu_com6年前
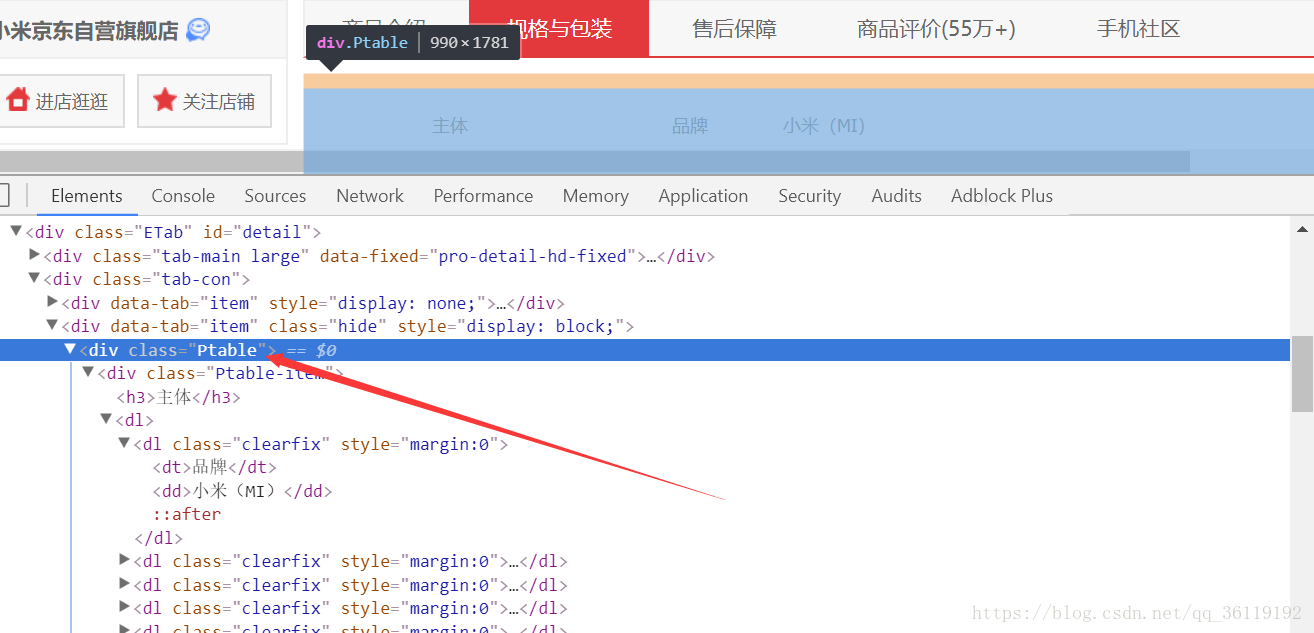
本文代码是使用python抓取京东小米8手机的配置信息 首先找到小米8商品的链接:https://item.jd.com/7437788.html 然后找到其配置信息的标签,我们找到其配...
yipeiwu_com6年前
爬虫思路 初步尝试 我先查看了network,并没有发现有可用的API;然后又用bs4去分析英雄列表页,但是请求到html里面,并没有英雄列表,在英雄列表的节点上,只有“正在加载中”这样...
yipeiwu_com6年前
Urllib 官方文档地址:https://docs.python.org/3/library/urllib.html urllib提供了一系列用于操作URL的功能。 本文主要介绍的是...
yipeiwu_com6年前
本文实例为大家分享了python爬取网易云音乐评论的具体代码,供大家参考,具体内容如下 import requests import bs4 import json def g...
yipeiwu_com6年前
python爬取淘宝商品销量的程序,运行程序,输入想要爬取的商品关键词,在代码中的‘###'可以进一步约束商品的属性,比如某某作者的书籍,可以在###处输入作者名字,以及时期等等。最后可...
yipeiwu_com6年前
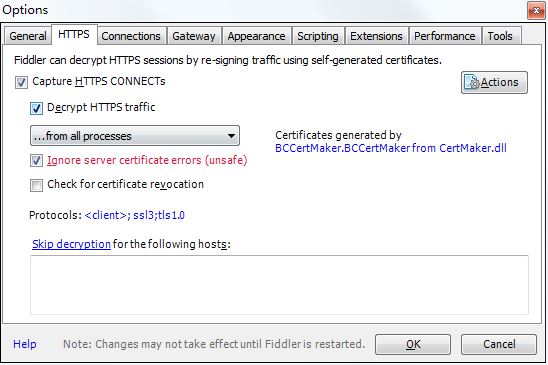
之前爬取都是网页上的数据,今天要来说一下怎么借助Fidder来爬取手机APP上的数据。 一、环境配置 1、Fidder的安装和配置 没有安装Fidder软件的可以进入 这个网址 下载,...
yipeiwu_com6年前
1. 背景 在使用selenium浏览器渲染技术,爬取网站信息时,一般来说,速度是很慢的。而且一般需要用到这种技术爬取的网站,反爬技术都比较厉害,对IP的访问频率应该有相当的限制。所以...
yipeiwu_com6年前
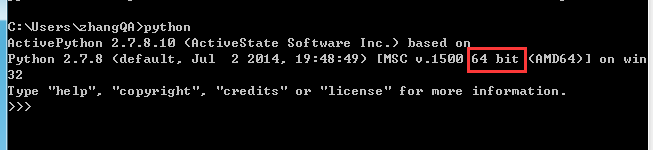
适用于python 2.7 64位安装 一、操作系统:WIN7 64位 二、python版本:2.7 64位(scrapy目前不支持3.x) 不确定位数的,看图 三、安装相关软件(可以...
yipeiwu_com6年前
摘要: 简介 asyncio可以实现单线程并发IO操作,是Python中常用的异步处理模块。关于asyncio模块的介绍,笔者会在后续的文章中加以介绍,本文将会讲述一个基于asyncio...