yipeiwu_com6年前
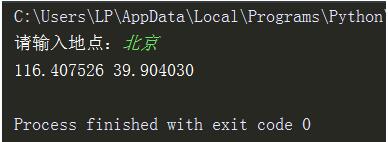
调用百度API获取经纬度信息。 import requests import json address = input('请输入地点:') par = {'address': add...
yipeiwu_com6年前
1、分析网站 打开开发者工具,我们观察到排行榜的数据并没有在doc里 doc文档 在Javascript里我么可以看到下面代码: ajax的post方法异步请求数据 在...
yipeiwu_com6年前
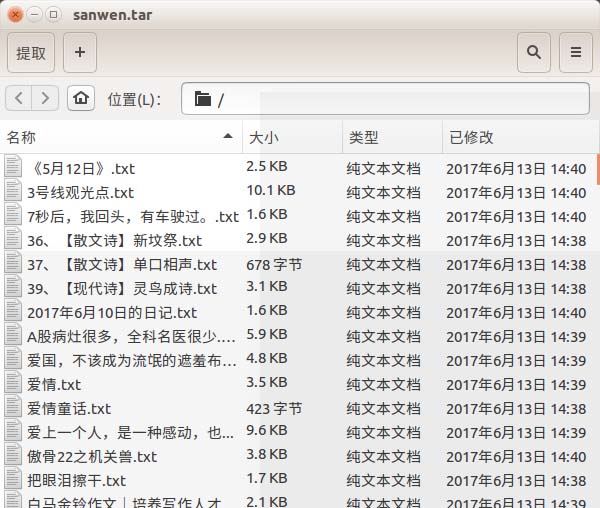
本文主要给大家介绍的是关于python爬取散文网文章的相关内容,分享出来供大家参考学习,下面一起来看看详细的介绍: 效果图如下: 配置python 2.7 bs4 requ...
yipeiwu_com6年前
翻看自己以前写的程序,发现写过一个爬取盘多多百度云资源的东西,完全是当时想看变形金刚才自己写的,而且当时第一次接触python大概写了有2天才搞出来这个程序,学习python语言,可以看...
yipeiwu_com6年前
本文实例讲述了Python实现的爬虫功能。分享给大家供大家参考,具体如下: 主要用到urllib2、BeautifulSoup模块 #encoding=utf-8 import re...
yipeiwu_com6年前
前言 最近网站从HTTPS转为HTTP,更换了网址,旧网址做了301重定向,折腾有点大,于是在百度站长平台提交网址,不管是主动推送还是手动提交,前提都是要整理网站的链接,手动添加太麻烦,...
yipeiwu_com6年前
前提: python3.4 windows 作用:通过搜狗的微信搜索接口http://weixin.sogou.com/来搜索相关微信文章,并将标题及相关链接导入Excel表格中 说明:...
yipeiwu_com6年前
本文实例讲述了Python实现简单的获取图片爬虫功能。分享给大家供大家参考,具体如下: 简单Python爬虫,获得网页上的照片 #coding=utf-8 import urllib...
yipeiwu_com6年前
Python 爬虫之超链接 url中含有中文出错及解决办法 python3.5 爬虫错误: UnicodeEncodeError: 'ascii' codec can't encod...
yipeiwu_com6年前
简单的写了一个爬取www.seebug.org上poc的小玩意儿~ 首先我们进行一定的抓包分析 我们遇到的第一个问题就是seebug需要登录才能进行下载,这个很好处理,只需要抓取返回值2...