yipeiwu_com6年前
本文实例讲述了Python实现抓取网页生成Excel文件的方法。分享给大家供大家参考,具体如下: Python抓网页,主要用到了PyQuery,这个跟jQuery用法一样,超级给力 示例...
yipeiwu_com6年前
1.Xpath Xpath是一门在XML中查找信息的语言,可用来在XML文档中对元素和属性进行遍历。XQuery和xpoint都是构建于xpath表达之上 2.节点 父(parent),...
yipeiwu_com6年前
前言 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。最近对python爬虫有了强烈地兴趣...
yipeiwu_com6年前
纪念我的第一个爬虫程序,一共写了三个白天,其中有两个上午没有看,中途遇到了各种奇怪的问题,伴随着他们的解决,对于一些基本的操作也弄清楚了。果然,对于这些东西的最号的学习方式,就是在使用中...
yipeiwu_com6年前
本文实例讲述了Python爬取需要登录的网站实现方法。分享给大家供大家参考,具体如下: import requests from lxml import html # 创建 sess...
yipeiwu_com6年前
本文实例讲述了Python3实现抓取javascript动态生成的html网页功能。分享给大家供大家参考,具体如下: 用urllib等抓取网页,只能读取网页的静态源文件,而抓不到由jav...
yipeiwu_com6年前
本例程使用urlib实现的,基于python2.7版本,采用beautifulsoup进行网页分析,没有第三方库的应该安装上之后才能运行,我用的IDE是pycharm,闲话少说,直接上代...
yipeiwu_com6年前
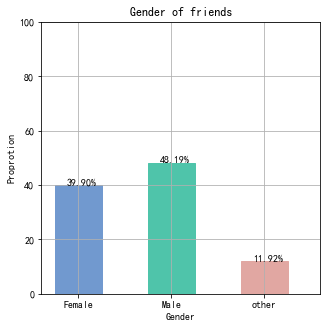
前几天无意中看到了一片文章,《用 Python 爬了爬自己的微信朋友(实例讲解)》,这篇文章写的是使用python中的itchat爬取微信中朋友的信息,其中信息包括,昵称、性别、地理位置...
yipeiwu_com6年前
课程体系结构: 1、Requests框架:自动爬取HTML页面与自动网络请求提交 2、robots.txt:网络爬虫排除标准 3、BeautifulSoup框架:解析HTML页面 4、R...
yipeiwu_com6年前
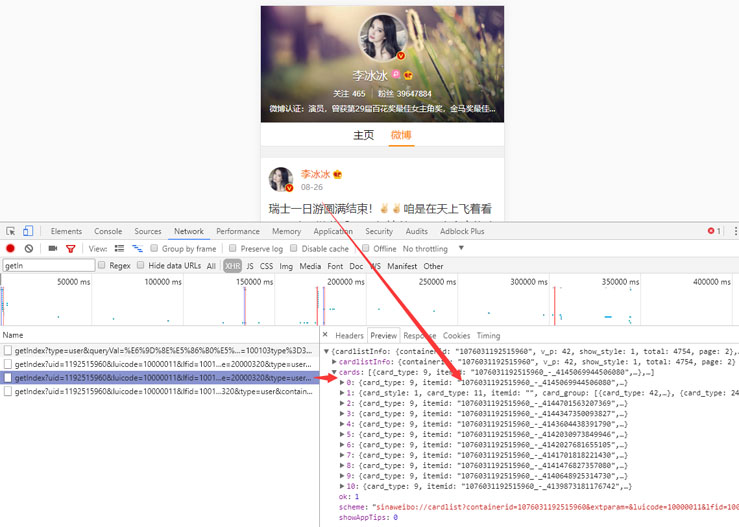
前言 在很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,一年一度的虐汪节,是继续蹲在角落默默...