利用Python3分析sitemap.xml并抓取导出全站链接详解
前言
最近网站从HTTPS转为HTTP,更换了网址,旧网址做了301重定向,折腾有点大,于是在百度站长平台提交网址,不管是主动推送还是手动提交,前提都是要整理网站的链接,手动添加太麻烦,效率低,于是就想写个脚本直接抓取全站链接并导出,本文就和大家一起分享如何使用python3实现抓取链接导出。

首先网站要有网站地图sitemap.xml文件地址,其次我这里用的是python3版本,如果你的环境是python2,需要对代码进行调整,因为python2和python3很多地方差别还是挺大的。
下面是python 3代码,将里面的链接地址换成你自己的网址即可:
#coding=utf-8
import urllib
import urllib.request import re
url='http://www.ranzhi.org/sitemap.xml'
html=urllib.request.urlopen(url).read()
html=html.decode('utf-8')
r=re.compile(r'(http://www.ranzhi.org.*?\.html)')
big=re.findall(r,html)
for i in big:
print(i)
op_xml_txt=open('xml.txt','a')
op_xml_txt.write('%s\n'%i)
我们能来看一下运行结果:
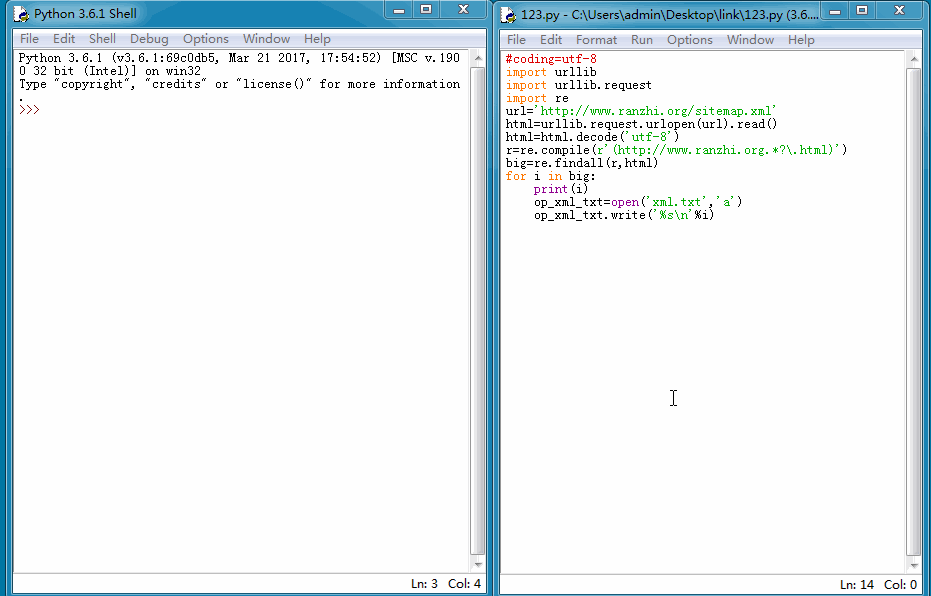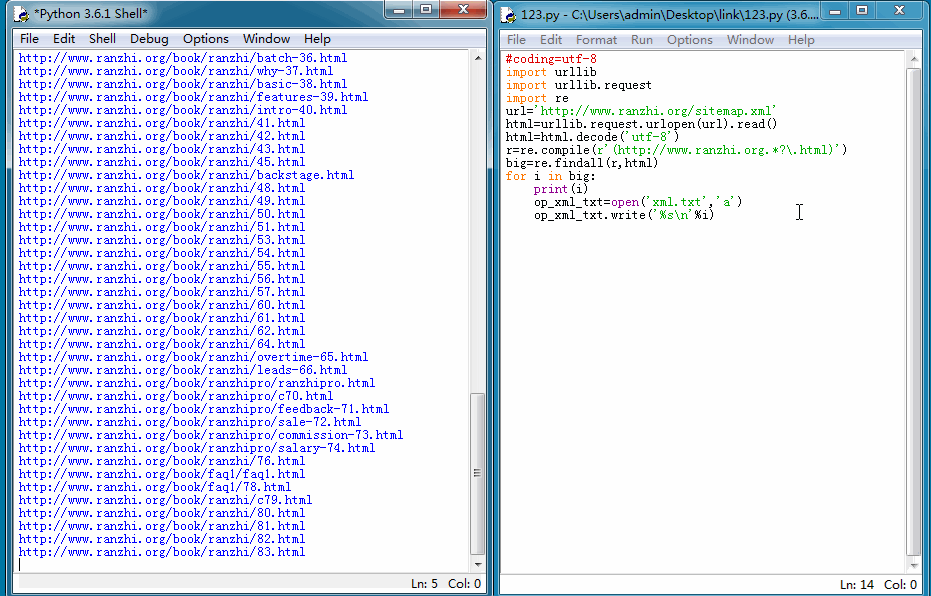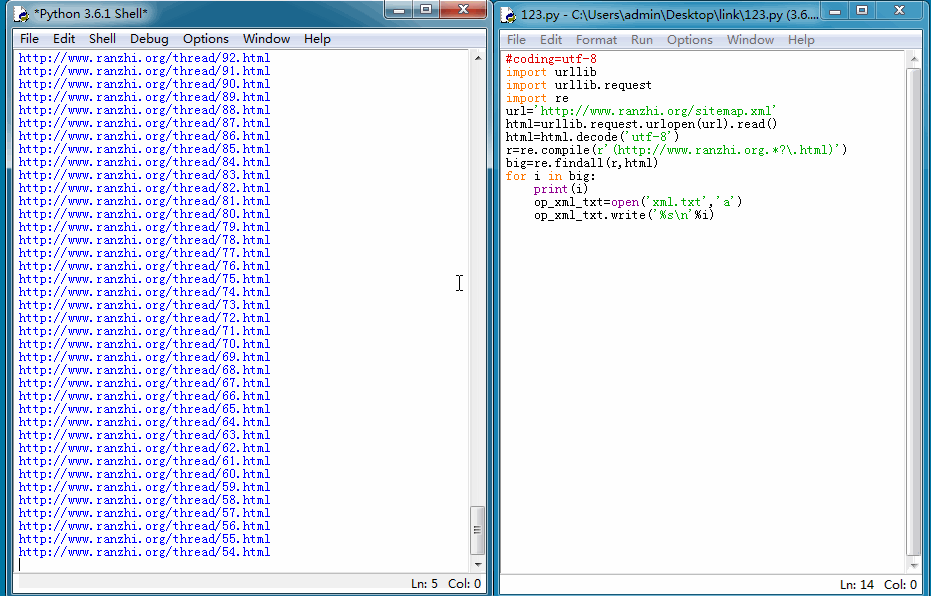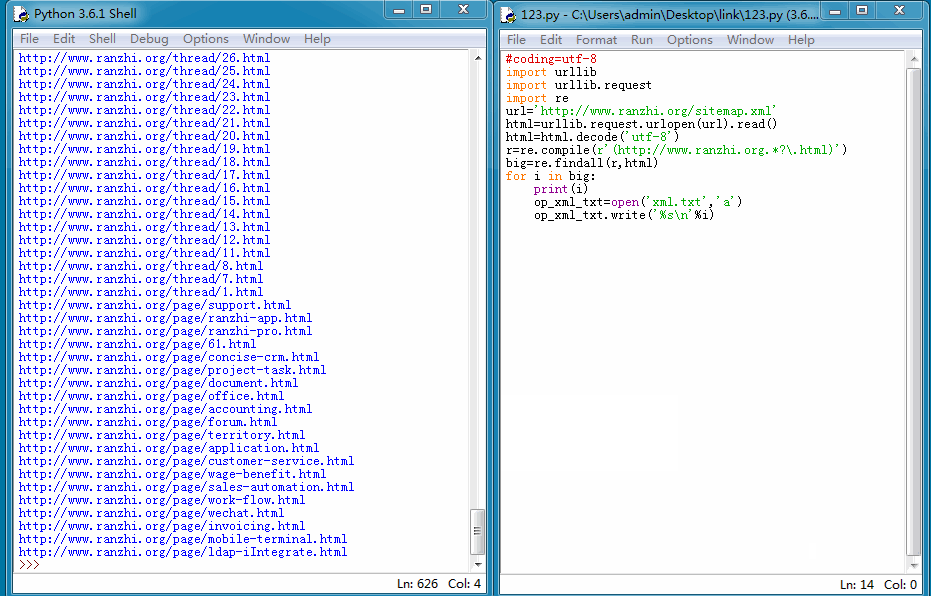
导出TXT格式文件后,再在百度站长平台手动提交就方便的多了。当然我们也可以使用更快的主动推送方式,因为我的网站是用PHP+mysql开发的,所以我们这里使用PHP脚本将上面抓取的链接再处理下,然后主动推送给百度,一遍加快爬虫抓取时间。
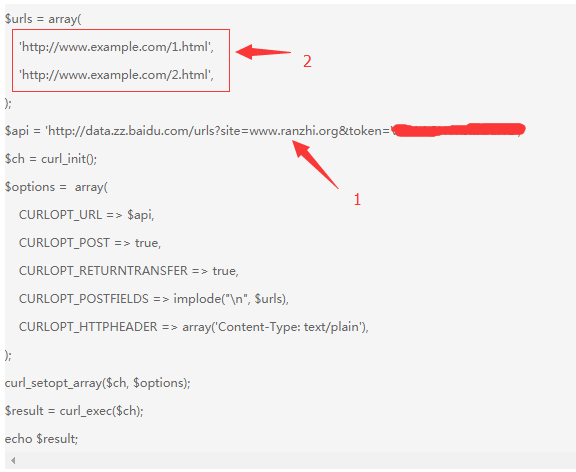
上面1是你的站点的主动推送API,这个可以在百度站长平台获取;2是要主动推送的网站地址,这里就可以用到我们上面抓取的全站链接了。将链接地址整理放到该数组中,运行一下个这个PHP脚本,就可以了。一键提交,及高效便捷,又能缩短爬虫爬去时间,有助于网站页面收录。
我们在平时的SEO或服务器运维工作中,时常会将重复工作自动化,复杂工作间变化,有助于提升效率,如果大家在操作过充中有何问题可以一起分享交流讨论。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对【听图阁-专注于Python设计】的支持。