



相关文章
python中数据爬虫requests库使用方法详解
一、什么是Requests Requests 是Python语编写,基于urllib,采Apache2 Licensed开源协议的 HTTP 库。它urllib 更加方便,可以节约我们大...
python实现博客文章爬虫示例
复制代码 代码如下:#!/usr/bin/python#-*-coding:utf-8-*-# JCrawler# Author: Jam <810441377@qq.com>...

python爬虫框架scrapy实现模拟登录操作示例
本文实例讲述了python爬虫框架scrapy实现模拟登录操作。分享给大家供大家参考,具体如下: 一、背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML、...
Python tornado队列示例-一个并发web爬虫代码分享
Queue Tornado的tornado.queue模块为基于协程的应用程序实现了一个异步生产者/消费者模式的队列。这与python标准库为多线程环境实现的queue模块类似。 一个协...
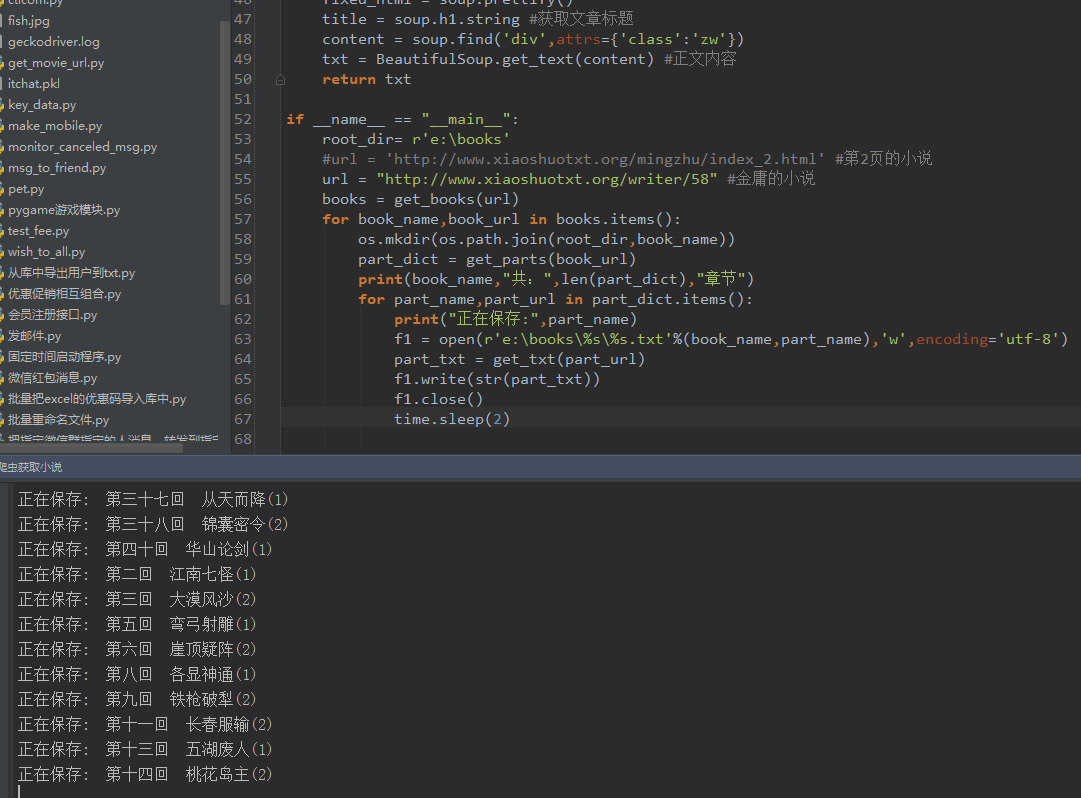
python实现爬虫抓取小说功能示例【抓取金庸小说】
本文实例讲述了python实现爬虫抓取小说功能。分享给大家供大家参考,具体如下: # -*- coding: utf-8 -*- from bs4 import BeautifulS...