python爬虫之百度API调用方法
调用百度API获取经纬度信息。
import requests
import json
address = input('请输入地点:')
par = {'address': address, 'key': 'cb649a25c1f81c1451adbeca73623251'}
url = 'http://restapi.amap.com/v3/geocode/geo'
res = requests.get(url, par)
json_data = json.loads(res.text)
geo = json_data['geocodes'][0]['location']
longitude = geo.split(',')[0]
latitude = geo.split(',')[1]
print(longitude,latitude)
其实调用API不难,这里是get方法,参数是地址和key,这个key是我在网上找的,应该是可以用的。
运行下代码。
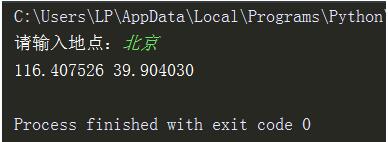
然后糗事百科的地址处理后,调用API即可获得经纬度,然后利用个人BDP即可完成该图。
以上这篇python爬虫之百度API调用方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。