python爬虫_自动获取seebug的poc实例
简单的写了一个爬取www.seebug.org上poc的小玩意儿~
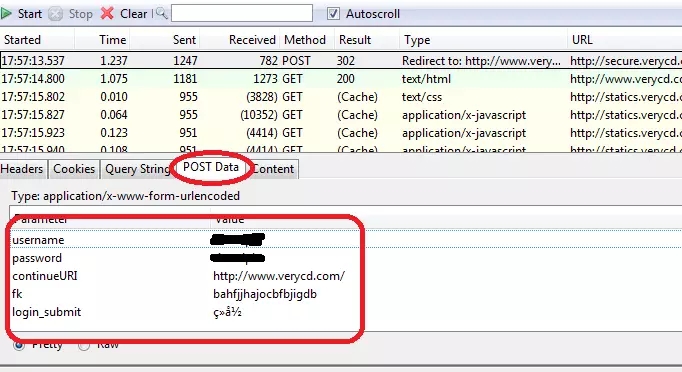
首先我们进行一定的抓包分析
我们遇到的第一个问题就是seebug需要登录才能进行下载,这个很好处理,只需要抓取返回值200的页面,将我们的headers信息复制下来就行了
(这里我就不放上我的headers信息了,不过headers里需要修改和注意的内容会在下文讲清楚)
headers = {
'Host':******,
'Connection':'close',
'Accept':******,
'User-Agent':******,
'Referer':'https://www.seebug.org/vuldb/ssvid-',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cookie':***********
}
由上所知,我们的中点就是referer这一项,是我们后面要进行修改的
那么怎么去修改这个呢?
我先进行点击下载链接抓包发现,seebug的poc下载链接特别的整齐:
'https://www.seebug.org/vuldb/downloadPoc/xxxxx',
后面只需要加上一个五位数就行,而且五位数是连号的哦!
这就一目了然,我更改了五位数再次进行请求时发现,并没有返回美丽的200状态码,瞄了一眼header,发现了referer这一项:
'Referer':'https://www.seebug.org/vuldb/ssvid-xxxxx'
也就是说referer这一项的五位数字也要随之变化,这样我们的get请求头部就完成了
接下来是线程的问题
使用了queue和threading进行多线程处理,发现我们不能图快,不然会被反爬虫发现
于是导入time增加time.sleep(1),能有一秒的休眠就行了,线程数给了2个(这样看来好像线程的意义并不大,不过也就这么写啦)
# coding=utf-8
import requests
import threading
import Queueimport time
headers = {
******
}
url_download = 'https://www.seebug.org/vuldb/downloadPoc/'
class SeeBugPoc(threading.Thread):
def __init__(self,queue):
threading.Thread.__init__(self)
self._queue = queue
def run(self):
while not self._queue.empty():
url_download = self._queue.get_nowait()
self.download_file(url_download)
def download_file(self,url_download):
r = requests.get(url = url_download,headers = headers)
print r.status_code
name = url_download.split('/')[-1]
print name
if r.status_code == 200:
f = open('E:/poc/'+name+'.txt','w')
f.write(r.content)
f.close()
print 'it ok!'
else:
print 'what fuck !'
time.sleep(1)
'''
def get_html(self,url):
r = requests.get(url = url,headers = headers)
print r.status_code
print time.time()
'''
def main():
queue = Queue.Queue()
for i in range(93000,93236):
headers['Referer'] = 'https://www.seebug.org/vuldb/ssvid-'+str(i)
queue.put('https://www.seebug.org/vuldb/downloadPoc/'+str(i))
#queue用来存放设计好的url,将他们放入一个队列中,以便后面取用
threads = []
thread_count = 2
for i in range(thread_count):
threads.append(SeeBugPoc(queue))
for i in threads:
i.start()
for i in threads:
i.join()
if __name__ == '__main__':
main()
代码如上
控制下载的range()中的两个五位数,大家只要去seebug库中找一找想要扫描的库的开头和结尾编码的五位数就行了(也就是他们的编号)
关于返回的状态码,如果项目不提供poc下载、poc下载不存在、poc需要兑换币才能下载,就不能够返回正常的200啦(非正常:404/403/521等)
当然,如果一直出现521,可以考虑刷新网页重新获取header并修改代码
最后进行一个状态码的判断,并且将200的文件写出来就好了
(
表示惭愧感觉自己写的很简单
如果大家发现错误或者有疑惑可以留言讨论哦
)
以上这篇python爬虫_自动获取seebug的poc实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。