yipeiwu_com6年前
1.使用系统自带库 os 这种方法的优点是,任何浏览器都能够使用, 缺点不能自如的打开一个又一个的网页 import os os.system('"C:/Program Files...
yipeiwu_com6年前
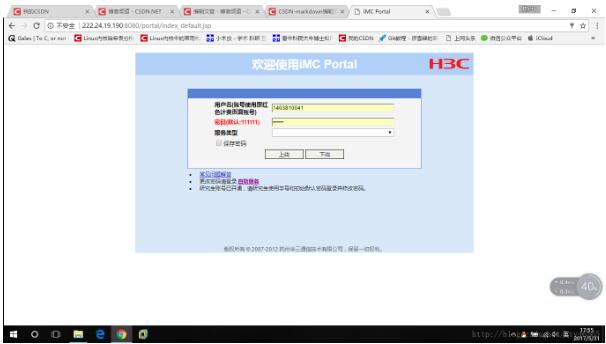
一、背景 最近学校校园网不知道是什么情况,总出现掉线的情况。每次掉线都需要我手动打开web浏览器重新进行账号密码输入,重新进行登录。系统的问题我没办法解决,但是可以写一个简单的pytho...
yipeiwu_com6年前
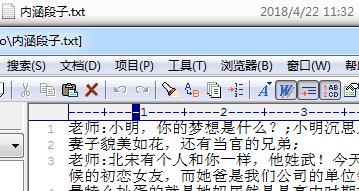
本文实例讲述了Python3使用正则表达式爬取内涵段子的方法。分享给大家供大家参考,具体如下: 似乎正则在爬虫中用的不是很广泛,但是也是基本功需要我们去掌握。 先将内涵段子网页爬取下来,...
yipeiwu_com6年前
分享给大家供大家参考,具体如下:Python3实现爬取指定百度贴吧页面并保存页面数据生成本地文档的方法。分享给大家供大家参考,具体如下: 首先我们创建一个python文件, tieba....
yipeiwu_com6年前
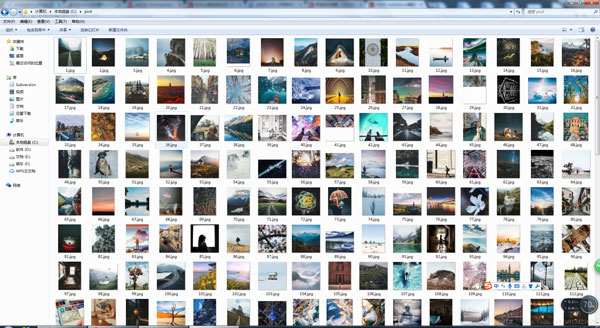
本文实例讲述了Python实现爬取百度贴吧帖子所有楼层图片的爬虫。分享给大家供大家参考,具体如下: 下载百度贴吧帖子图片,好好看 python2.7版本: #coding=utf-...
yipeiwu_com6年前
实例如下所示: import time import pickle import os import re class LogIncScaner(object): def __i...
yipeiwu_com6年前
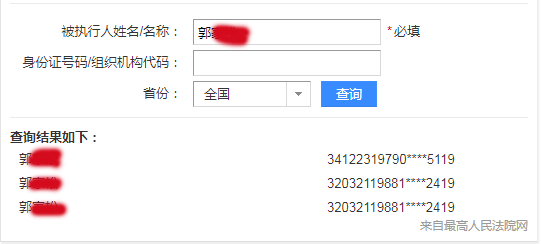
本文实例讲述了Python爬虫实现全国失信被执行人名单查询功能。分享给大家供大家参考,具体如下: 一、需求说明 利用百度的接口,实现一个全国失信被执行人名单查询功能。输入姓名,查询是否在...
yipeiwu_com6年前
0x00 环境 系统环境:win10 编写工具:JetBrains PyCharm Community Edition 2017.1.2 x64 python 版本:python-3.6...
yipeiwu_com6年前
Pyspider 中采用了 tornado 库来做 http 请求,在请求过程中可以添加各种参数,例如请求链接超时时间,请求传输数据超时时间,请求头等等,但是根据pyspider的原始框...
yipeiwu_com6年前
1.python爬虫浏览器伪装 #导入urllib.request模块 import urllib.request #设置请求头 headers=("User-Agent","Moz...