python爬虫_实现校园网自动重连脚本的教程
一、背景
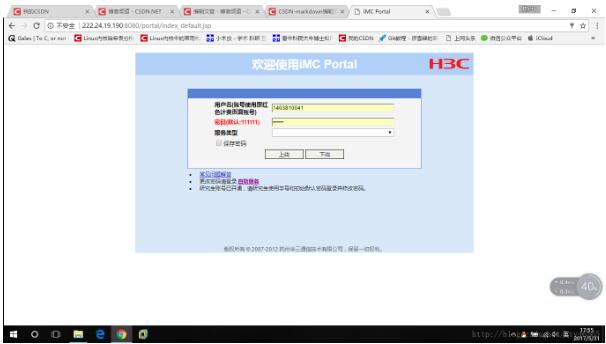
最近学校校园网不知道是什么情况,总出现掉线的情况。每次掉线都需要我手动打开web浏览器重新进行账号密码输入,重新进行登录。系统的问题我没办法解决,但是可以写一个简单的python脚本用于自动登录校园网。每次掉线后,再打开任意网页就是这个页面。
二、实现代码
#-*- coding:utf-8 -*-
__author__ = 'pf'
import time
import requests
class Login:
#初始化
def __init__(self):
#检测间隔时间,单位为秒
self.every = 10
#模拟登录
def login(self):
print self.getCurrentTime(), u"拼命连网中..."
url="http://222.24.19.190:8080/portal/pws?t=li"
#消息头
headers={
'Host':"222.24.19.190:8080",
'User-Agent':"Mozilla/5.0 (Windows NT 6.3; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0",
'Accept':"application/json, text/javascript, */*; q=0.01",
'Accept-Language':"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
'Accept-Encoding':"gzip, deflate",
'Referer':"http://222.24.19.190:8080/portal/index_default.jsp",
'Content-Type':"application/x-www-form-urlencoded",
'X-Requested-With':"XMLHttpRequest",
'Content-Length':"291",
'Connection':"close"
}
#提交的信息
payload={
'userName':'1403810041',
'userPwd':'MTk4NDEy',
'userurl':'http%3A%2F%2Fwww.msn.com%3Focid%3Dwispr&userip=222.24.52.200',
'portalProxyIP':'222.24.19.190',
'portalProxyPort':'50200',
'dcPwdNeedEncrypt':'1',
'assignIpType':'0',
'appRootUrl':'=http%3A%2F%2F222.24.19.190%3A8080%2Fportal%2F',
'manualUrlEncryptKey':'rTCZGLy2wJkfobFEj0JF8A%3D%3D'
}
try:
r=requests.post(url,headers=headers,data=payload)
print self.getCurrentTime(),u'连上了...现在开始看连接是否正常'
except:
print("error")
#判断当前是否可以连网
def canConnect(self):
try:
q=requests.get("http://www.baidu.com")
if(q.status_code==200):
return True
else:
return False
except:
print 'error'
#获取当前时间
def getCurrentTime(self):
return time.strftime('[%Y-%m-%d %H:%M:%S]',time.localtime(time.time()))
#主函数
def main(self):
print self.getCurrentTime(), u"Hi,欢迎使用自动登陆系统"
while True:
self.login()
while True:
can_connect = self.canConnect()
if not can_connect:
print self.getCurrentTime(),u"断网了..."
self.login()
else:
print self.getCurrentTime(), u"一切正常..."
time.sleep(self.every)
time.sleep(self.every)
login = Login()
login.main()
三、解决步骤
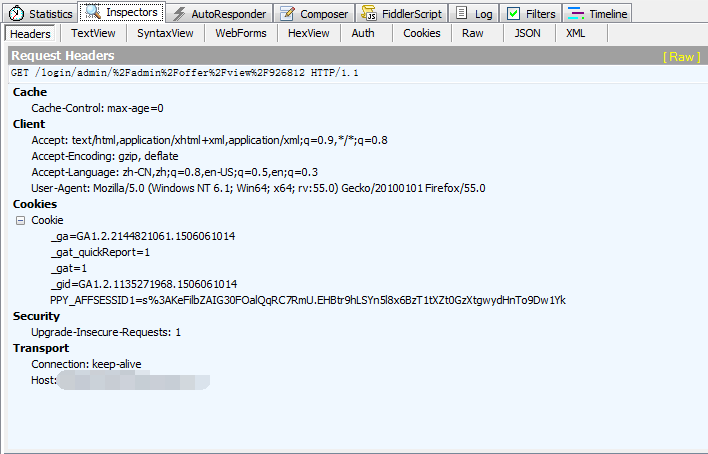
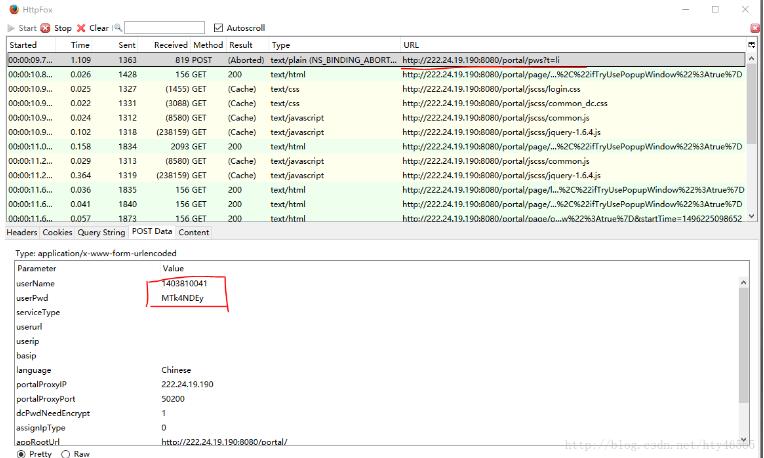
首先需要一个用于抓包的工具。我们要抓取提交的数据以及提交到的url地址。我这里用的是firefox浏览器的httpfox插件。
用firefox浏览器打开登录页面,并且打开httpfox插件。在页面中输入账户名和密码点击上线后,注意一下httpfox中有一行记录的Method是POST。我们需要记录的就是其中的POST Data中的userName和userPwd。以及Headers中的数据。还有POST到的URL地址。
如图:

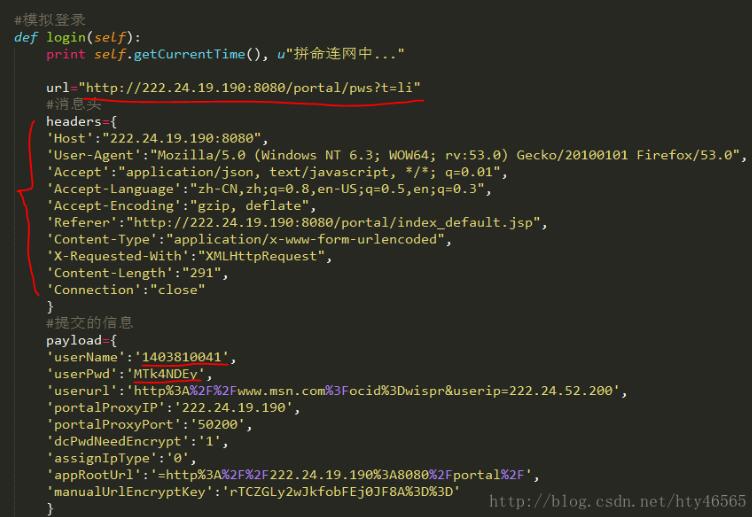
我这里使用了python中的requests库。
将获取到的URL地址、userName、userPwd、Headers填入代码中对应的位置。
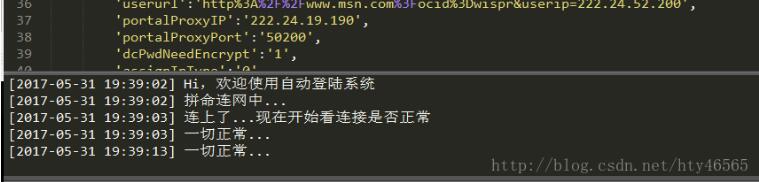
可以直接运行python程序,如图:
或者可以用pyinstaller库生成exe文件再运行,如图:

四、总结
我这里设置了一个死循环,让程序每隔10s检测一下是否能连上网,若可以连上则输出“一切正常”然后接着循环,若不能连上,则输出“断网了”然后重新连网。我们可以对程序设置开机自启动。这样,开机也就不需要再手动去连网了。
以上这篇python爬虫_实现校园网自动重连脚本的教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。