Python3使用正则表达式爬取内涵段子示例
本文实例讲述了Python3使用正则表达式爬取内涵段子的方法。分享给大家供大家参考,具体如下:
似乎正则在爬虫中用的不是很广泛,但是也是基本功需要我们去掌握。
先将内涵段子网页爬取下来,之后利用正则进行匹配,匹配完成后将匹配的段子写入文本文档内。代码如下:
# -*- coding:utf-8 -*-
from urllib import request as urllib2
import re
# 利用正则表达式爬取内涵段子
url = r'http://www.neihanpa.com/article/list_5_{}.html'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0',
}
file_name = '内涵段子.txt'
for page in range(2):
# 2表示页数,可以自行调整
fullurl = url.format(str(page+1))
request = urllib2.Request(url=fullurl, headers=headers)
response = urllib2.urlopen(request)
html = response.read().decode('gbk')
# re.S 如果没有re.S 则是只匹配一行有没有符合规则的字符串,如果没有则下一行重新匹配
# 如果加上re.S 则是将所有的字符串作为一个整体进行匹配
pattern = re.compile(r'<div\sclass="f18 mb20">(.*?)</div>',re.S)
duanzis = pattern.findall(html)
for duanzi in duanzis:
duanzi = duanzi.replace('<p>','').replace('</p>','').replace('<br />','\n').replace('“','').replace('&rdquo','').replace('…','')
try:
# 将爬取的段子写入文件
file = open(file_name,'a',encoding='utf-8')
file.write('\n'.join(duanzi.split()))
file.close()
except OSError as e:
print(e)
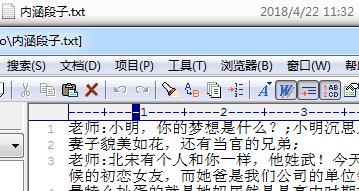
运行后生成如下图所示文件:
PS:这里再为大家提供2款非常方便的正则表达式工具供大家参考使用:
JavaScript正则表达式在线测试工具:
http://tools.jb51.net/regex/javascript
正则表达式在线生成工具:
http://tools.jb51.net/regex/create_reg
更多关于Python相关内容可查看本站专题:《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。