yipeiwu_com6年前
python书籍信息爬虫示例,供大家参考,具体内容如下 背景说明 需要收集一些书籍信息,以豆瓣书籍条目作为源,得到一些有效书籍信息,并保存到本地数据库。 获取书籍分类标签 具体可参考这个...
yipeiwu_com6年前
注:答案一般在网上都能够找到。 1.对if __name__ == 'main'的理解陈述 2.python是如何进行内存管理的? 3.请写出一段Python代码实现删除一个lis...
yipeiwu_com6年前
HTML文档是互联网上的主要文档类型,但还存在如TXT、WORD、Excel、PDF、csv等多种类型的文档。网络爬虫不仅需要能够抓取HTML中的敏感信息,也需要有抓取其他类型文档的能力...
yipeiwu_com6年前
使用python爬虫其实就是方便,它会有各种工具类供你来使用,很方便。Java不可以吗?也可以,使用httpclient工具、还有一个大神写的webmagic框架,这些都可以实现爬虫,只...
yipeiwu_com6年前
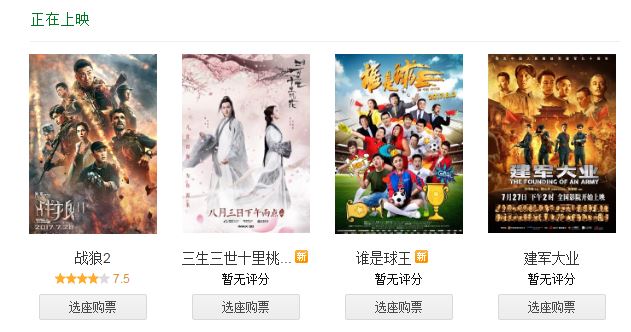
刚接触python不久,做一个小项目来练练手。前几天看了《战狼2》,发现它在最新上映的电影里面是排行第一的,如下图所示。准备把豆瓣上对它的影评做一个分析。 目标总览 主要做了三件事:...
yipeiwu_com6年前
本文实例为大家分享了Python爬取网络图片的具体代码,供大家参考,具体内容如下 代码: import urllib import urllib.request import re...
yipeiwu_com6年前
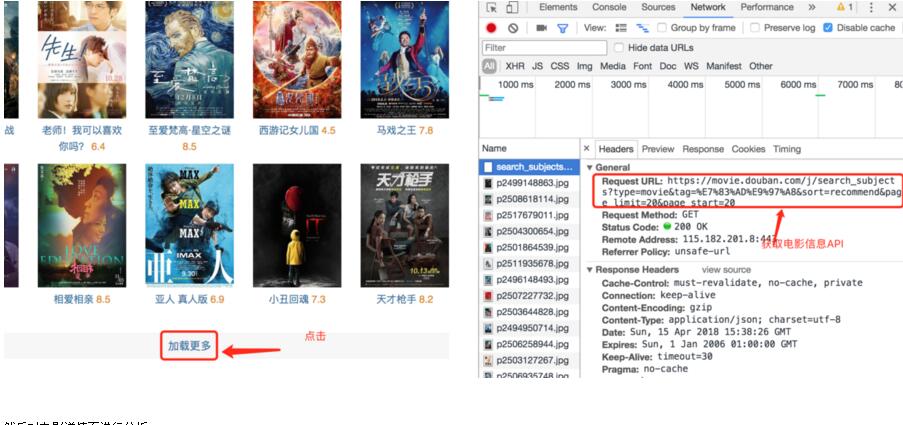
本文实例为大家分享了python网络爬虫的笔记,供大家参考,具体内容如下 (一) 三种网页抓取方法 1、 正则表达式: 模块使用C语言编写,速度快,但...
yipeiwu_com6年前
有时候使用python从网站上爬数据的时候,如果数据里包含中文,有时候显示的却是如下所示...\xe4\xba\xba\xef\xbc\x8c\xe6...类似与国际化 解决方法:...
yipeiwu_com6年前
概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识。 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web站点的行为...
yipeiwu_com6年前
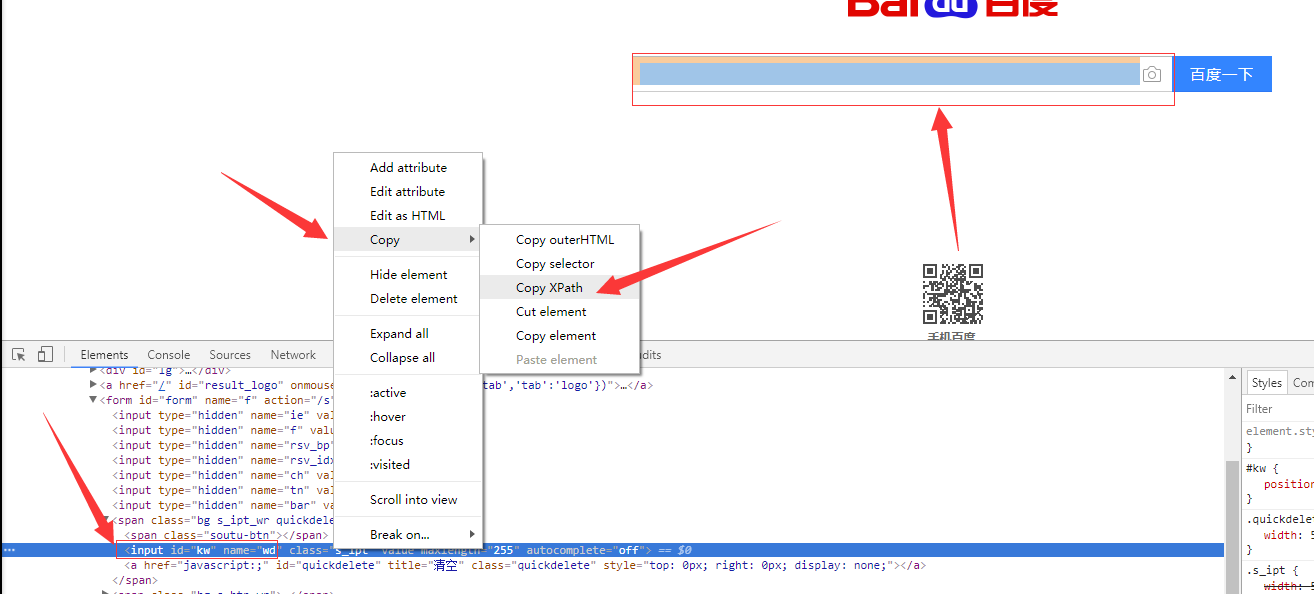
一、简介 XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuer...