yipeiwu_com6年前
案例:爬取使用搜狗根据指定词条搜索到的页面数据(例如爬取词条为‘周杰伦'的页面数据) import urllib.request # 1.指定url url = 'https://w...
yipeiwu_com6年前
需求:爬取搜狗首页的页面数据 import requests # 1.指定url url = 'https://www.sogou.com/' # 2.发起get请求:get方法会返...
yipeiwu_com6年前
urllib模块发起的POST请求 案例:爬取百度翻译的翻译结果 1.通过浏览器捉包工具,找到POST请求的url 针对ajax页面请求的所对应url获取,需要用到浏览器的捉包工具。...
yipeiwu_com6年前
这篇文章主要介绍了python爬虫 批量下载zabbix文档代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 # -*- c...
yipeiwu_com6年前
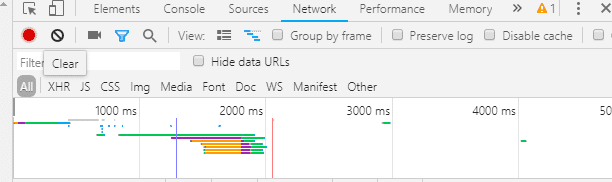
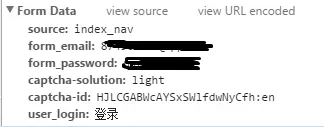
思路 一、想要实现登录豆瓣关键点 分析真实post地址 ----寻找它的formdata,如下图,按浏览器的F12可以找到。 实战操作 实现:模拟登录豆瓣,验证码处理,登录...
yipeiwu_com6年前
原生请求头字符串 raw_headers = """Host: open.tool.hexun.com Pragma: no-cache Cache-Control: no-cach...
yipeiwu_com6年前
平时见到的url参数都是key-value, 一般vlaue都是字符串类型的 如果有幸和我一样遇到字典,列表等参数,那么就幸运了 python2代码 import json from...
yipeiwu_com6年前
看着自己少得可怜的访问量,突然有一个想用爬虫刷访问量的想法,主要也是抱着尝试的心态,学习学习。 其实市面上有一些软件可以代刷流量 比如 流量精灵,使用感确实比我们自己写的代码要好一些 第...
yipeiwu_com6年前
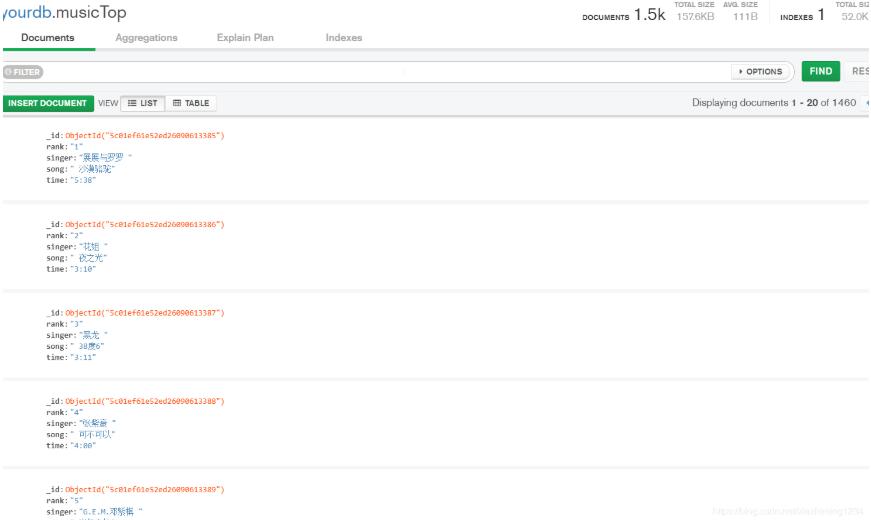
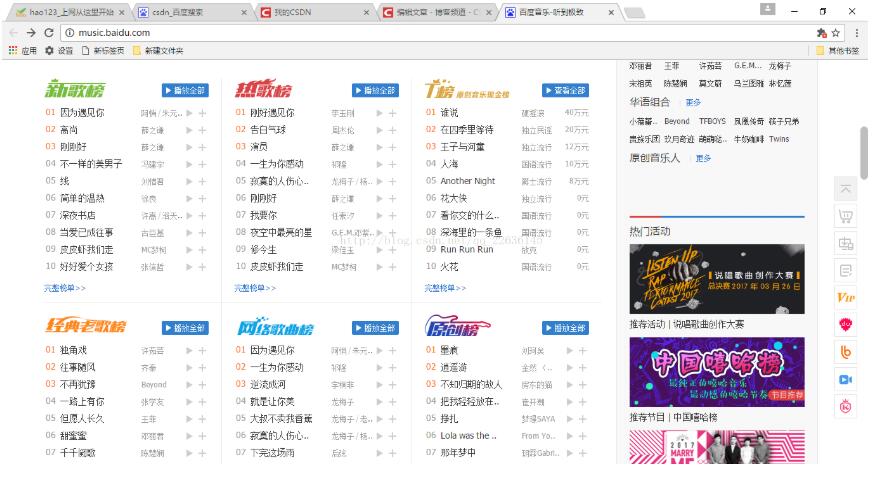
爬取TOP500的音乐信息,包括排名情况、歌曲名、歌曲时间。 网页版酷狗不能手动翻页进行下一步的浏览,仔细观察第一页的URL: http://www.kugou.com/yy/rank/...
yipeiwu_com6年前
在上次的爬虫中,抓取的数据主要用到的是第三方的Beautifulsoup库,然后对每一个具体的数据在网页中的selecter来找到它,每一个类别便有一个select方法。对网页有过接触的...