python爬虫 urllib模块发起post请求过程解析
urllib模块发起的POST请求
案例:爬取百度翻译的翻译结果
1.通过浏览器捉包工具,找到POST请求的url
针对ajax页面请求的所对应url获取,需要用到浏览器的捉包工具。查看百度翻译针对某个字条发送ajax请求,所对应的url
点击clear按钮可以把抓包工具,所抓到请求清空
然后填上翻译字条发送ajax请求,红色框住的都是发送的ajax请求
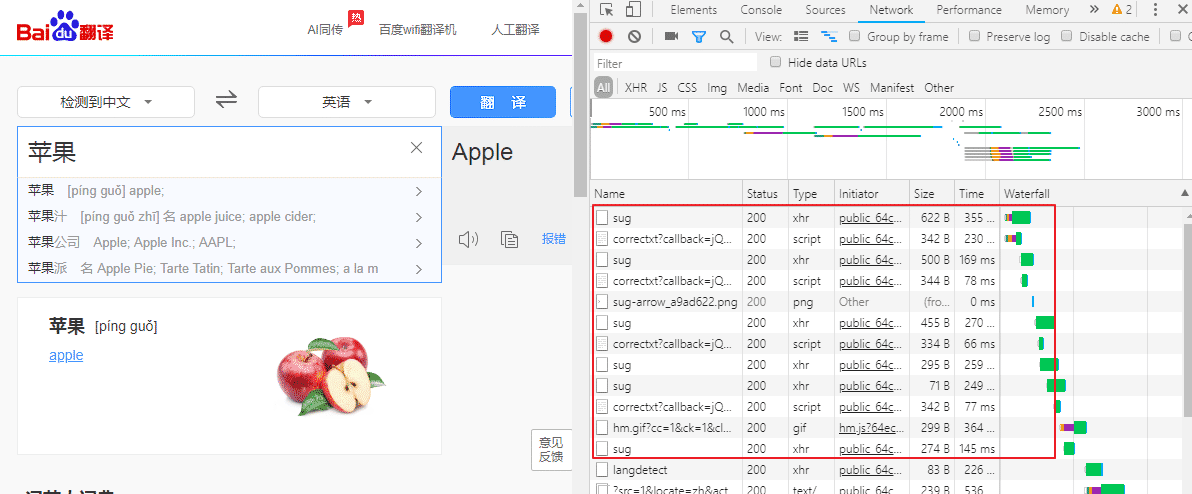
抓包工具All按钮代表 显示抓到的所有请求 ,包括GET、POST请求 、基于ajax的POST请求
XHR代表 只显示抓到的基于ajax的POST请求
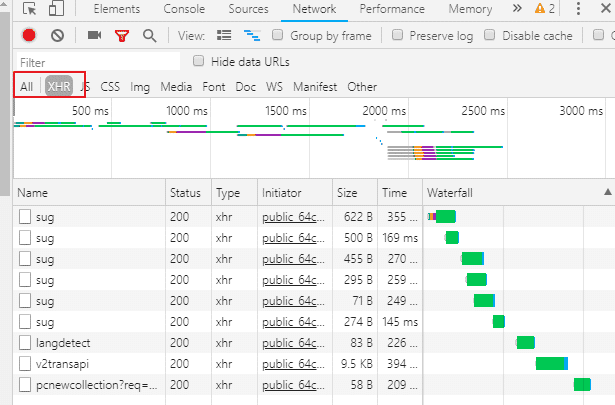
哪个才是我们所要的基于ajax的POST请求,这个POST请求是携带翻译字条的苹果请求参数
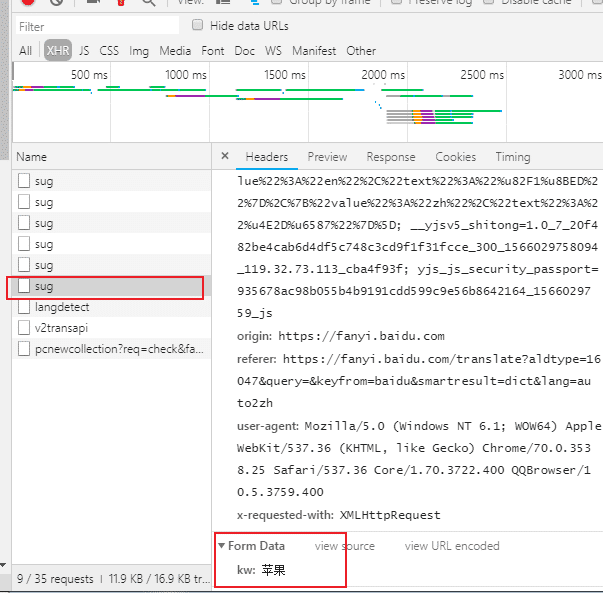
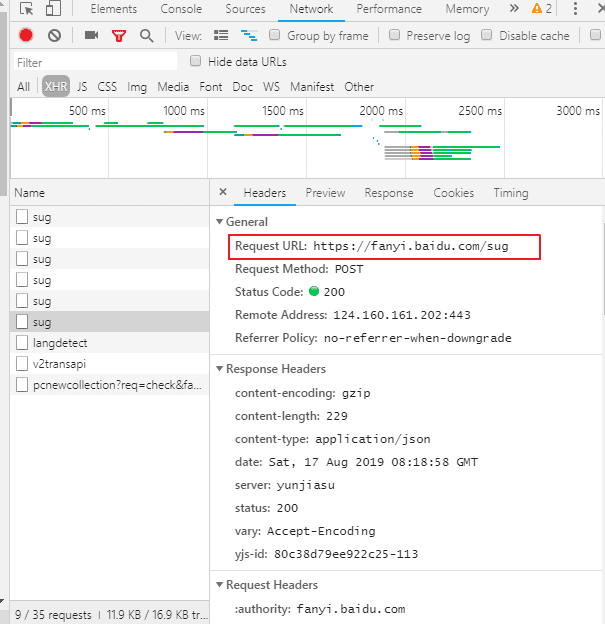
再看看这个POST请求 对应的请求URL ,这个URL是我们要请求的URL
发起POST请求之前,要处理POST请求携带的参数 3步流程:
一、将POST请求封装到字典
二、使用parse模块中的urlencode(返回值类型是字符串类型)进行编码处理
三、将步骤二的编码结果转换成byte类型
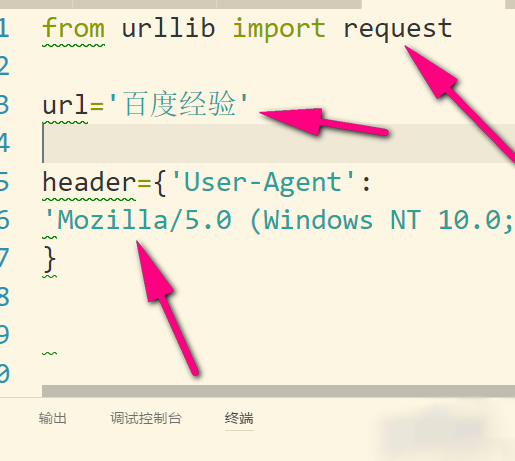
import urllib.request
import urllib.parse
# 1.指定url
url = 'https://fanyi.baidu.com/sug'
# 发起POST请求之前,要处理POST请求携带的参数 流程:
# 一、将POST请求封装到字典
data = {
# 将POST请求所有携带参数放到字典中
'kw':'苹果',
}
# 二、使用parse模块中的urlencode(返回值类型是字符串类型)进行编码处理
data = urllib.parse.urlencode(data)
# 三、将步骤二的编码结果转换成byte类型
data = data.encode()
'''2. 发起POST请求:urlopen函数的data参数表示的就是经过处理之后的
POST请求携带的参数
'''
response = urllib.request.urlopen(url=url,data=data)
data = response.read()
print(data)
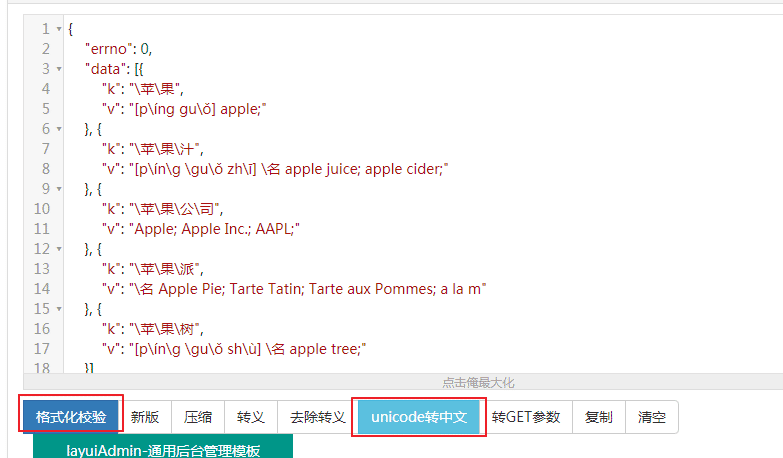
把拿到的翻译结果 去json在线格式校验(在线JSON校验格式化工具(Be JSON)),
点击格式化校验和unicode转中文
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。