yipeiwu_com6年前
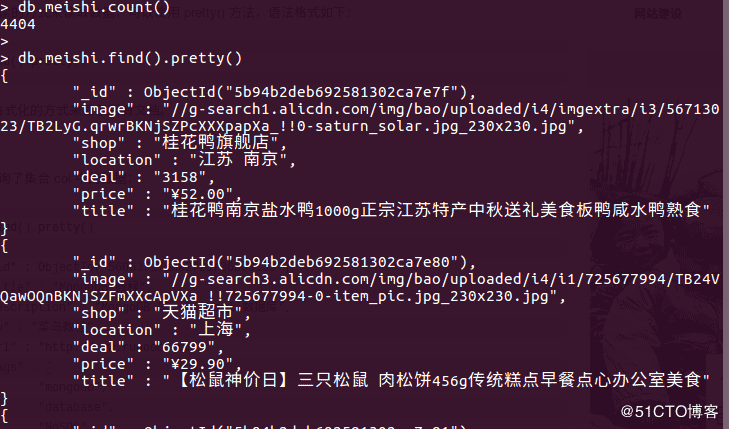
环境: ubuntu16.04 python3.5 python库: selenium, pyquery,pymongo, re 要求: 设置×××面浏览器访问,并将商品列表存入mo...
yipeiwu_com6年前
在用爬虫爬取网站数据时,有些站点的一些关键数据的获取需要使用账号登录,这里可以使用requests发送登录请求,并用Session对象来自动处理相关Cookie。 另外在登录时,有些网站...
yipeiwu_com6年前
抓取豆瓣影评评分 正常的抓取 分析请求的url https://movie.douban.com/subject/26322642/comments?start=20&limit=...
yipeiwu_com6年前
介绍 本文将展示如何利用Python爬虫来实现诗歌接龙。 该项目的思路如下: 利用爬虫爬取诗歌,制作诗歌语料库; 将诗歌分句,形成字典:键(key)为该句首字的拼音,值(value)为...
yipeiwu_com6年前
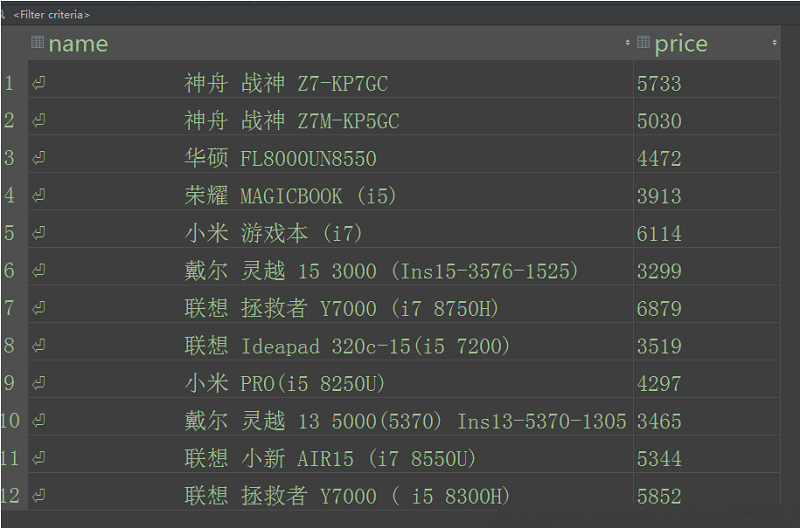
对于动态数据的爬取,可以选择selenium和PhantomJS两种方式,本文选择的是PhantomJS。 网址: https://s.taobao.com/search?q=笔记本电...
yipeiwu_com6年前
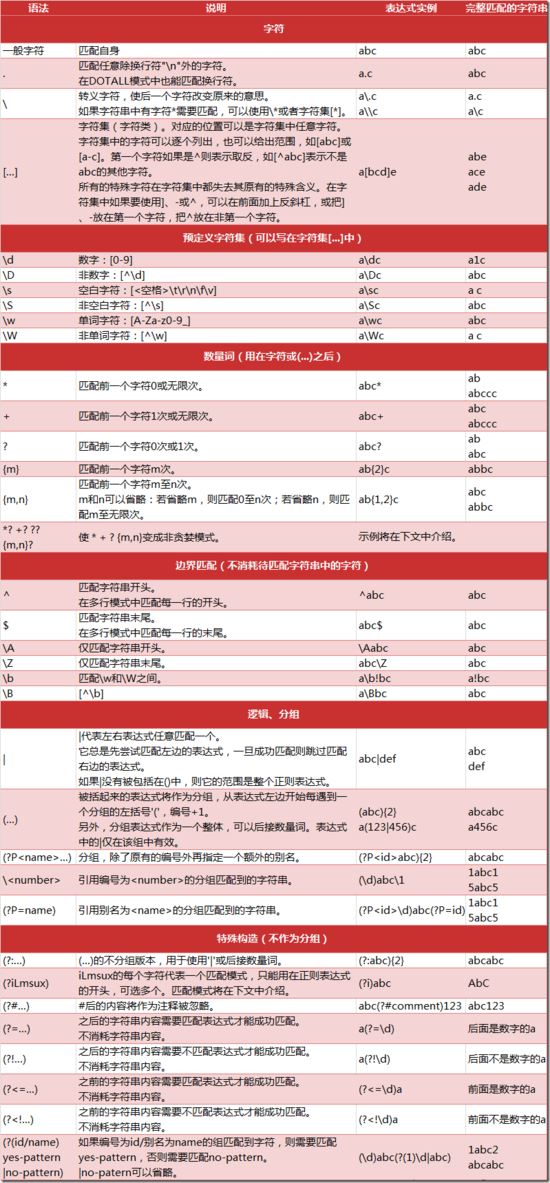
正则表达式的使用 re.match(pattern,string,flags=0) re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回...
yipeiwu_com6年前
近日,有朋友向我求助一件小事儿,他在一个短视频app上看到一个好玩儿的段子,想下载下来,可死活找不到下载的方法。这忙我得帮,少不得就抓包分析了一下这个app,找到了视频的下载链接,帮他解...
yipeiwu_com6年前
具体代码如下所示: #coding=utf8 from urllib import request import re import urllib,os url='http://t...
yipeiwu_com6年前
作为初学爬虫的我,无论是爬取文字还是图片,都可以游刃有余的做到,但是爬虫所爬取的内容往往不是单独的图片或者文字,于是我就想是否可以将图文保存至world文档里,一开始使用了如下方法保存图...
yipeiwu_com6年前
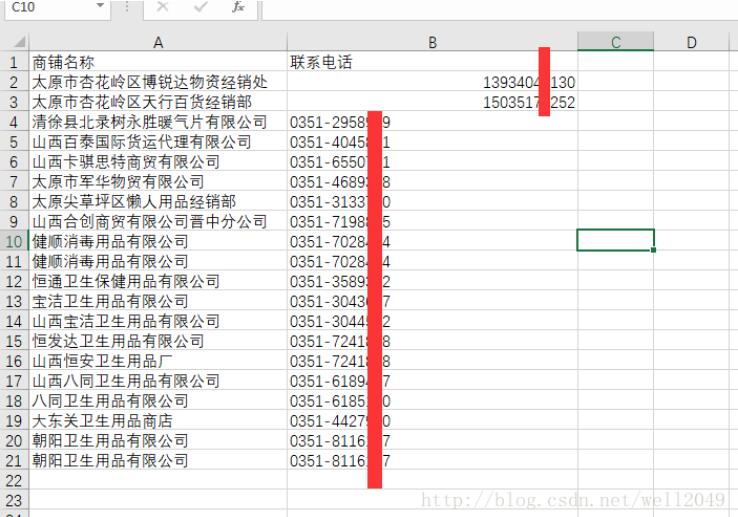
上次学会了爬取图片,这次就想着试试爬取商家的联系电话,当然,这里纯属个人技术学习,爬取过后及时删除,不得用于其它违法用途,一切后果自负。 首先我学习时用的是114黄页数据。 下面四个是用...