Python爬取商家联系电话以及各种数据的方法
上次学会了爬取图片,这次就想着试试爬取商家的联系电话,当然,这里纯属个人技术学习,爬取过后及时删除,不得用于其它违法用途,一切后果自负。
首先我学习时用的是114黄页数据。
下面四个是用到的模块,前面2个需要安装一下,后面2个是python自带的。
import requests from bs4 import BeautifulSoup import csv import time
然后,写个函数获取到页面种想要的数据,记得最后的return返回一下,因为下面的函数要到把数据写到csv里面。
def get_content(url,data=None):
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36',
}
r = requests.get(url, headers=header)
soup = BeautifulSoup(r.content, 'html.parser')
data = soup.body.find('div',{'id':'news_con'})
ul = data.find('ul')
lis = ul.find_all('li')
pthons=[]
for item in lis:
rows=[]
name= item.find('h4').string
rows.append(name)
tel = item.find_all("div")[2].string
rows.append(tel)
pthons.append(rows)
time.sleep(1)
return pthons
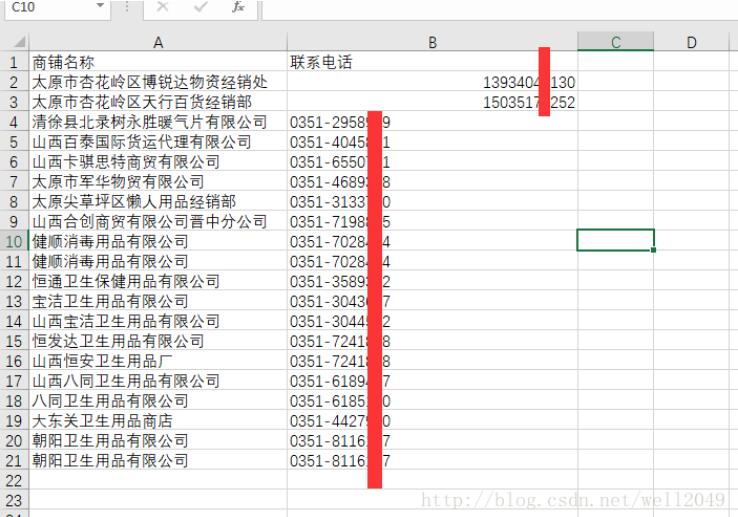
接着:把数据写到表格里面。我这里用到的是csv,方便阅览。
def write_data(data,name):
file_name=name
with open(file_name, "w", newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["商铺名称", "联系电话"])
writer.writerows(data)
print('抓取完成')
最后就是执行这些函数:
if __name__ == '__main__': url = 'http://ty.114chn.com/CustomerInfo/Customers?cid=008004008&page=2' mydata = get_content(url) write_data(mydata,'phone.csv')
在这里我想到应该把url写成动态的,因为这里面有页数。让page写成循环自动+1,当然,可以在网页看到一共多少页。写个循环执行。就更完美了。
以上这篇Python爬取商家联系电话以及各种数据的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。