使用Python抓取豆瓣影评数据的方法
抓取豆瓣影评评分
正常的抓取
分析请求的url
里面有用的也就是start和limit参数,我尝试过修改limit参数,但是没有效果,可以认为是默认的
start参数是用来设置从第几条数据开始查询的
- 设计查询列表,发现页面中有url中的查询部分,且指向下一个页面

于是采用下面的代码进行判断是否还有下一个页面
if next_url:
visit_URL('https://movie.douban.com/subject/24753477/comments'+next_url)
- 用requests发送请求,beautifulsoup进行网页解析
把数据写入txt
import requests
from bs4 import BeautifulSoup
first_url = 'https://movie.douban.com/subject/26322642/comments?status=P'
# 请求头部
headers = {
'Host':'movie.douban.com',
'Referer':'https://movie.douban.com/subject/24753477/?tag=%E7%83%AD%E9%97%A8&from=gaia_video',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
}
def visit_URL(url):
res = requests.get(url=url,headers=headers)
soup = BeautifulSoup(res.content,'html5lib')
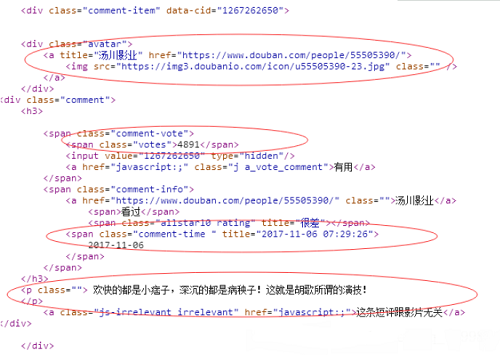
div_comment = soup.find_all('div',class_='comment-item') # 找到所有的评论模块
for com in div_comment:
username = com.find('div',class_='avatar').a['title']
comment_time = com.find('span',class_='comment-time')['title']
votes = com.find('span',class_='votes').get_text()
comment = com.p.get_text()
with open('1.txt','a',encoding='utf8') as file:
file.write('评论人:'+username+'\n')
file.write('评论时间:'+comment_time+'\n')
file.write('支持人数:'+votes+'\n')
file.write('评论内容:'+comment+'\n')
# 检查是否有下一页
next_url = soup.find('a',class_='next')
if next_url:
temp = next_url['href'].strip().split('&') # 获取下一个url
next_url = ''.join(temp)
print(next_url)
# print(next_url)
if next_url:
visit_URL('https://movie.douban.com/subject/24753477/comments'+next_url)
if __name__ == '__main__':
visit_URL(first_url)
模仿移动端
很多时候模仿移动端获得的页面会比PC端的简单,更加容易解析,这次模拟移动端,发现可以直接访问api获取json格式的数据,nice!

至于怎么模拟移动端只需要将user-agent修改为移动端的头
useragents = [ "Mozilla/5.0 (iPhone; CPU iPhone OS 9_2 like Mac OS X) AppleWebKit/601.1 (KHTML, like Gecko) CriOS/47.0.2526.70 Mobile/13C71 Safari/601.1.46", "Mozilla/5.0 (Linux; U; Android 4.4.4; Nexus 5 Build/KTU84P) AppleWebkit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30", "Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0)"
怎么获取这些头部?用火狐的插件user-agent switcher
之后的操作就是解析json
import random
import requests
import json
import time
first_url = 'https://m.douban.com/rexxar/api/v2/tv/26322642/interests?count=20&order_by=hot&start=0&ck=dNhr&for_mobile=1'
url = 'https://m.douban.com/rexxar/api/v2/tv/26322642/interests'
# 移动端头部信息
useragents = [
"Mozilla/5.0 (iPhone; CPU iPhone OS 9_2 like Mac OS X) AppleWebKit/601.1 (KHTML, like Gecko) CriOS/47.0.2526.70 Mobile/13C71 Safari/601.1.46",
"Mozilla/5.0 (Linux; U; Android 4.4.4; Nexus 5 Build/KTU84P) AppleWebkit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0)"
]
def visit_URL(i):
print(">>>>>",i)
# 请求头部
headers = {
'Host':'m.douban.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':random.choice(useragents)
}
params = {
'count':'50',
'order_by':'hot',
'start':str(i),
'for_mobile':'1',
'ck':'dNhr'
}
res = requests.get(url=url,headers=headers,params=params)
res_json = res.json()
interests = res_json['interests']
print(len(interests))
for item in interests:
with open('huge.txt','a',encoding='utf-8') as file:
if item['user']:
if item['user']['name']:
file.write('评论用户:'+item['user']['name']+'\n')
else:
file.write('评论用户:none\n')
if item['create_time']:
file.write('评论时间:'+item['create_time']+'\n')
else:
file.write('评论时间:none\n')
if item['comment']:
file.write('评论内容:'+item['comment']+'\n')
else:
file.write('评论内容:none\n')
if item['rating']:
if item['rating']['value']:
file.write('对电影的评分:'+str(item['rating']['value'])+'\n\n')
else:
file.write('对电影的评分:none\n')
if __name__ == '__main__':
for i in range(0,66891,20):
# time.sleep(2)
visit_URL(i)
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对【听图阁-专注于Python设计】的支持。如果你想了解更多相关内容请查看下面相关链接