python3实现爬取淘宝美食代码分享
环境:
ubuntu16.04
python3.5
python库: selenium, pyquery,pymongo, re
要求:
设置×××面浏览器访问,并将商品列表存入mongoDB数据库.
分析过程暂时略过
代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
1.爬取淘宝美食的流程
- 搜索关键字: 用selenium打开浏览器,模拟输入关键字,并搜索对应的商品列表.
- 分析页码并翻页,模拟翻页,查看到所有页面的商品列表.
- 分析并提取商品,利用Pyquery分析源码,解析得到商品列表.
- 存储到MONGODB数据库,将商品列表信息存储到mongoDB数据库.
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
import re
from anli.mongoconfig import *
import pymongo
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
#设置×××面访问
opt = webdriver.FirefoxOptions()
opt.set_headless()
browser = webdriver.Firefox(options=opt)
#等待浏览器加载页面成功.
wait = WebDriverWait(browser,10)
def search():
try:
# 后台打开浏览器
browser.get('https://www.taobao.com')
# 用CSS选择器复制搜索框
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#q'))
)
# 找到搜索按钮.
submit = wait.until(
# EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm .search-button')))
EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))
# 输入关键字
input.send_keys('美食')
# 点击搜索按钮.
submit.click()
# 输出总共的页数.
total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.total')))
# 调取商品列表的函数.
get_products()
return total.text
except TimeoutException: #超时错误.
return search()
# 翻页
def next_page(page_number):
try:
#注意在firefox和chrome浏览器复制出来的元素不太一样.
#要传入的页码: 到第几页
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'input.input:nth-child(2)'))
)
#复制确定按钮的元素:
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'span.btn:nth-child(4)')))
#清除页码
input.clear()
#输入当前页码
input.send_keys(page_number)
#点击确定按钮.
submit.click()
#判断当前页码是否是当前数字: 复制高亮页码数.
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'span.num'),str(page_number)))
get_products()
except TimeoutException:
next_page(page_number)
#解析jquery源码
def get_products():
#商品列表:
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-itemlist .items .item')))
# 获取网页源码
html = browser.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
#定义商品列表详细信息的字典
product = {
'title': item.find('.title').text(),
'price': item.find('.price').text(),
'image': item.find('.pic .img').attr('src'),
'shop': item.find('.shop').text(),
'deal': item.find('.deal-cnt').text()[:-3],
'location': item.find('.location').text()
}
print(product)
#将商品列表信息保存到mongoDB数据库.
save_to_mongo(product)
def save_to_mongo(result):
try:
if db[MONGO_TABLE].insert(result):
print('存储到mongodb成功',result)
except Exception:
print('存储到mongodb失败',result)
def main():
total = search()
# 用正则表达式只匹配出数字,并打印数字.
total = int(re.compile('(\d+)').search(total).group(1))
print(total)
for i in range(2,total + 1):
next_page(i)
if __name__=='__main__':
main()
#关闭×××面浏览器.
browser.quit()
#mongoconfig.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
MONGO_URL = 'localhost'
MONGO_DB = 'taobao'
MONGO_TABLE = 'meishi'
安装和使用mongodb参考:
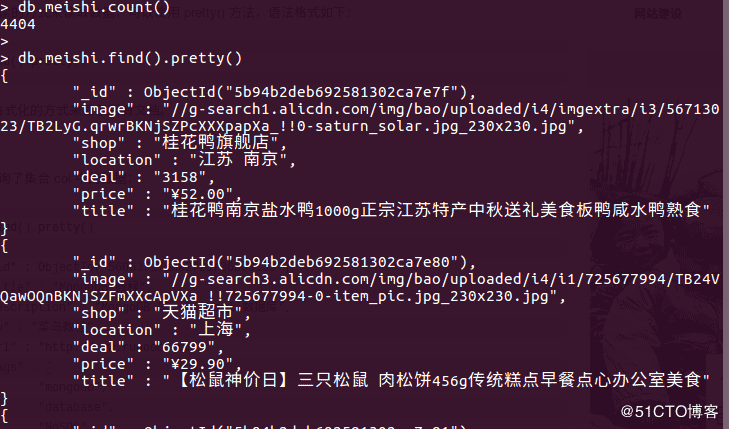
实现效果:
注意:
chrome浏览器和firefox浏览器的网页元素不太一样.