yipeiwu_com6年前
本文实例讲述了Python使用爬虫爬取静态网页图片的方法。分享给大家供大家参考,具体如下: 爬虫理论基础 其实爬虫没有大家想象的那么复杂,有时候也就是几行代码的事儿,千万不要把自己吓倒了...
yipeiwu_com6年前
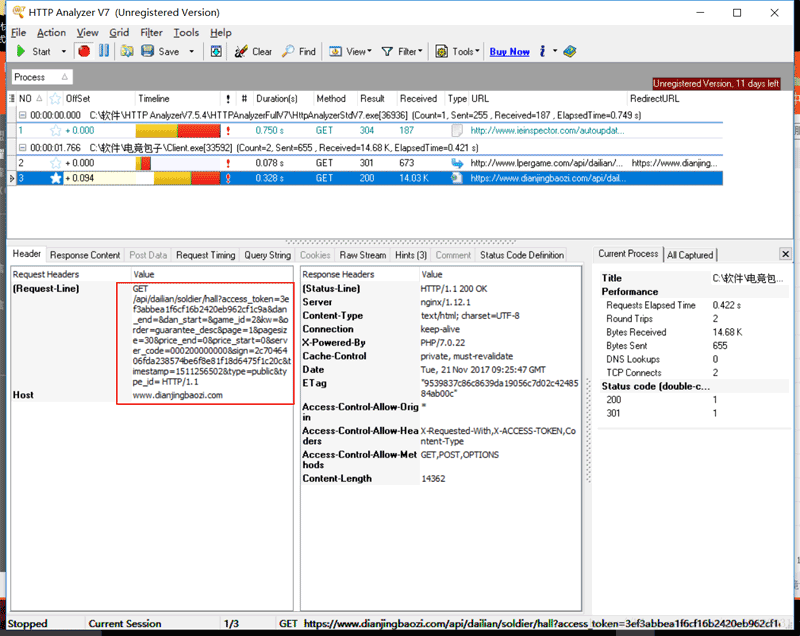
本文实例讲述了Python3实现的爬虫爬取数据并存入mysql数据库操作。分享给大家供大家参考,具体如下: 爬一个电脑客户端的订单。罗总推荐,抓包工具用的是HttpAnalyzerStd...
yipeiwu_com6年前
本文实例讲述了Python实现的爬取网易动态评论操作。分享给大家供大家参考,具体如下: 打开网易的一条新闻的源代码后,发现并没有所要得评论内容。 经过学习后发现,源代码只是一个完整页面的...
yipeiwu_com6年前
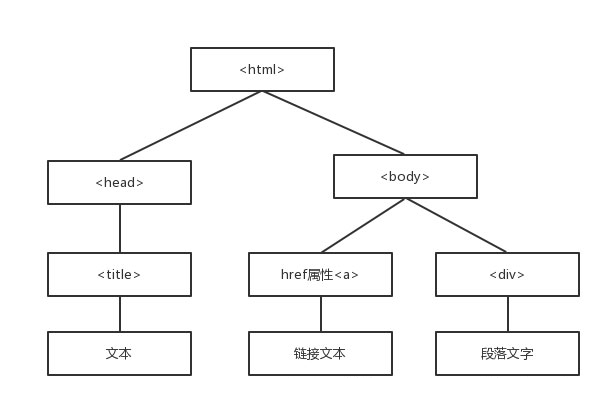
本文实例讲述了Python简单实现网页内容抓取功能。分享给大家供大家参考,具体如下: 使用模块: import urllib2 import urllib 普通抓取实例:...
yipeiwu_com6年前
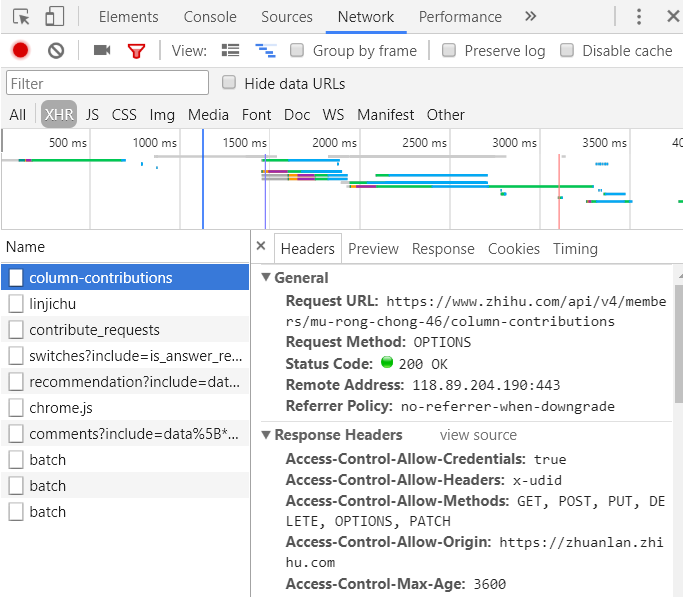
本文实例讲述了Python实现的爬虫刷回复功能。分享给大家供大家参考,具体如下: 最近闲的无聊,就想着去看看爬虫,顺着爬虫顺利的做到了模拟登录、刷帖子等等,这里简要说一下。 使用Pyth...
yipeiwu_com6年前
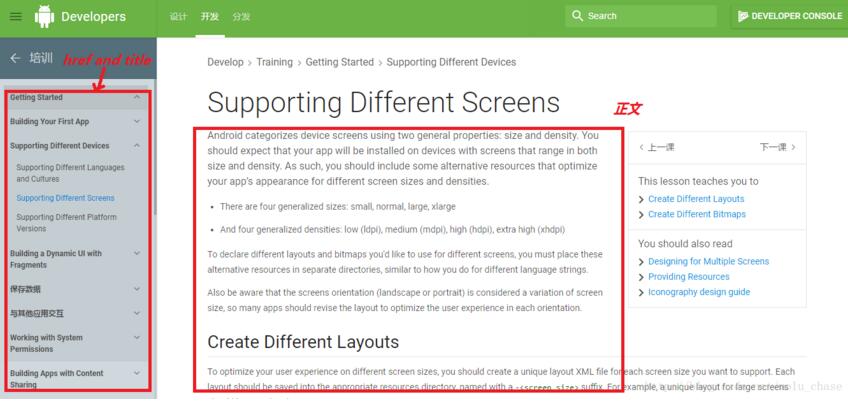
爬虫的起因 官方文档或手册虽然可以查阅,但是如果变成纸质版的岂不是更容易翻阅与记忆。如果简单的复制粘贴,不知道何时能够完成。于是便开始想着将Android的官方手册爬下来。 全篇的实...
yipeiwu_com6年前
本文实例为大家分享了python爬取网页内容转换为PDF的具体代码,供大家参考,具体内容如下 将廖雪峰的学习教程转换成PDF文件,代码只适合该网站,如果需要其他网站的教程,可靠需要进行...
yipeiwu_com6年前
前言 最近学完Python,写了几个爬虫练练手,网上的教程有很多,但是有的已经不能爬了,主要是网站经常改,可是爬虫还是有通用的思路的,即下载数据、解析数据、保存数据。下面一一来讲。 1...
yipeiwu_com6年前
Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象、直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二...
yipeiwu_com6年前
刚开始学python,记录下问题。 代码如下: #coding:utf-8 import re,urllib2 def getHTML(url): html=urllib2.ur...