Python简单实现网页内容抓取功能示例
本文实例讲述了Python简单实现网页内容抓取功能。分享给大家供大家参考,具体如下:
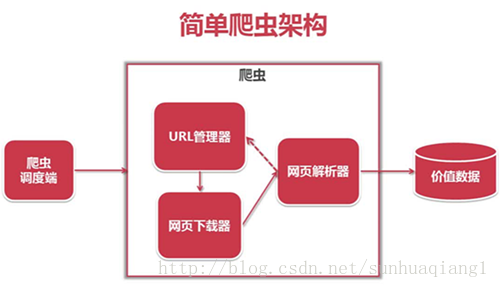
使用模块:
import urllib2 import urllib
普通抓取实例:
#!/usr/bin/python # -*- coding: UTF-8 -*- import urllib2 url = 'http://www.baidu.com' #创建request对象 request = urllib2.Request(url) #发送请求,获取结果 try: response = urllib2.urlopen(request) except BaseException, err: print err exit() #获取状态码,如果是200表示获取成功 code = response.getcode() print code #读取内容 if 200 == code: content = response.read() print content
Get请求抓取实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib2
import urllib
#urllib2使用GET方式的请求
url = 'http://www.baidu.com/s'
values = {'wd' : '车云'}
# 必须编码
data = urllib.urlencode(values)
url = url + '?' + data
print url
#url == http://www.baidu.com/s?wd=%E8%BD%A6%E4%BA%91
#创建request对象
request = urllib2.Request(url)
#发送请求,获取结果
try:
response = urllib2.urlopen(request)
except BaseException, err:
print err
exit()
#获取状态码,如果是200表示获取成功
code = response.getcode()
print code
#读取内容
if 200 == code:
content = response.read()
print content
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。