python爬取网页转换为PDF文件
爬虫的起因
官方文档或手册虽然可以查阅,但是如果变成纸质版的岂不是更容易翻阅与记忆。如果简单的复制粘贴,不知道何时能够完成。于是便开始想着将Android的官方手册爬下来。
全篇的实现思路
- 分析网页
- 学会使用BeautifulSoup库
- 爬取并导出
参考资料:
* 把廖雪峰的教程转换为PDF电子书
* Requests文档
* Beautiful Soup文档
配置
在Ubuntu下使用Pycharm运行成功
转PDF需要下载wkhtmltopdf
具体过程
网页分析
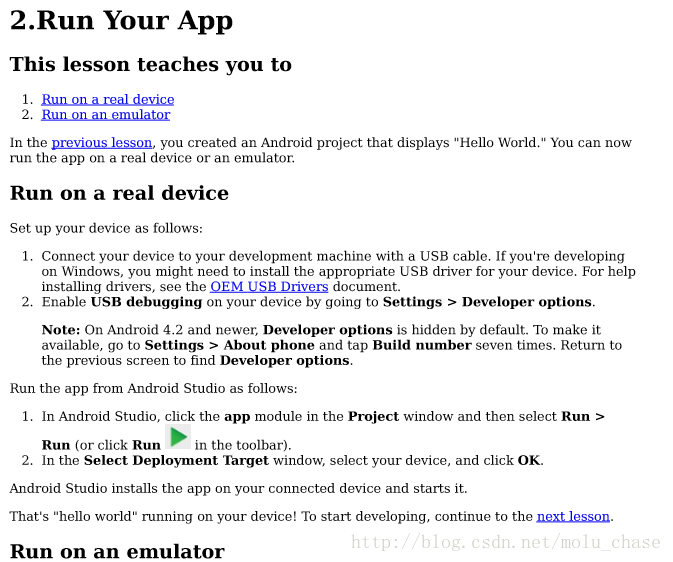
如下所示的一个网页,要做的是获取该网页的正文和标题,以及左边导航条的所有网址
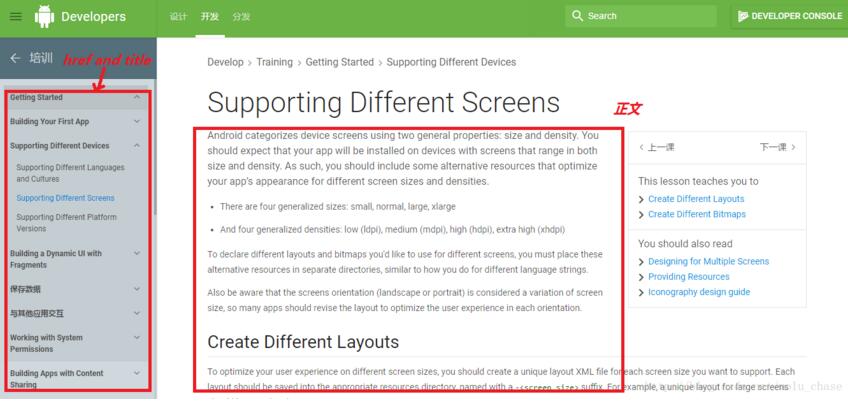
接下来的工作就是找到这些标签喽…
关于Requests的使用
详细参考文档,这里只是简单的使用Requests获取html以及使用代理翻墙(网站无法直接访问,需要VPN)
proxies={
"http":"http://vpn的IP:port",
"https":"https://vpn的IP:port",
}
response=requests.get(url,proxies=proxies)
Beautiful Soup的使用
参考资料里面有Beautiful Soup文档,将其看完后,可以知道就讲了两件事:一个是查找标签,一个是修改标签。
本文需要做的是:
1. 获取标题和所有的网址,涉及到的是查找标签
#对标签进行判断,一个标签含有href而不含有description,则返回true
#而我希望获取的是含有href属性而不含有description属性的<a>标签,(且只有a标签含有href)
def has_href_but_no_des(tag):
return tag.has_attr('href') and not tag.has_attr('description')
#网页分析,获取网址和标题
def parse_url_to_html(url):
response=requests.get(url,proxies=proxies)
soup=BeautifulSoup(response.content,"html.parser")
s=[]#获取所有的网址
title=[]#获取对应的标题
tag=soup.find(id="nav")#获取第一个id为"nav"的标签,这个里面包含了网址和标题
for i in tag.find_all(has_href_but_no_des):
s.append(i['href'])
title.append(i.text)
#获取的只是标签集,需要加html前缀
htmls = "<html><head><meta charset='UTF-8'></head><body>"
with open("android_training_3.html",'a') as f:
f.write(htmls)
对上面获取的网址分析,获取正文,并将图片取出存于本地;涉及到的是查找标签和修改属性
#网页操作,获取正文及图片
def get_htmls(urls,title):
for i in range(len(urls)):
response=requests.get(urls[i],proxies=proxies)
soup=BeautifulSoup(response.content,"html.parser")
htmls="<div><h1>"+str(i)+"."+title[i]+"</h1></div>"
tag=soup.find(class_='jd-descr')
#为image添加相对路径,并下载图片
for img in tag.find_all('img'):
im = requests.get(img['src'], proxies=proxies)
filename = os.path.split(img['src'])[1]
with open('image/' + filename, 'wb') as f:
f.write(im.content)
img['src']='image/'+filename
htmls=htmls+str(tag)
with open("android_training_3.html",'a') as f:
f.write(htmls)
print(" (%s) [%s] download end"%(i,title[i]))
htmls="</body></html>"
with open("android_training_3.html",'a') as f:
f.write(htmls)
2.转为PDF
这一步需要下载wkhtmltopdf,在Windows下执行程序一直出错..Ubuntu下可以
def save_pdf(html):
"""
把所有html文件转换成pdf文件
"""
options = {
'page-size': 'Letter',
'encoding': "UTF-8",
'custom-header': [
('Accept-Encoding', 'gzip')
]
}
pdfkit.from_file(html, "android_training_3.pdf", options=options)
最后的效果图
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。