python爬虫正则表达式之处理换行符
刚开始学python,记录下问题。
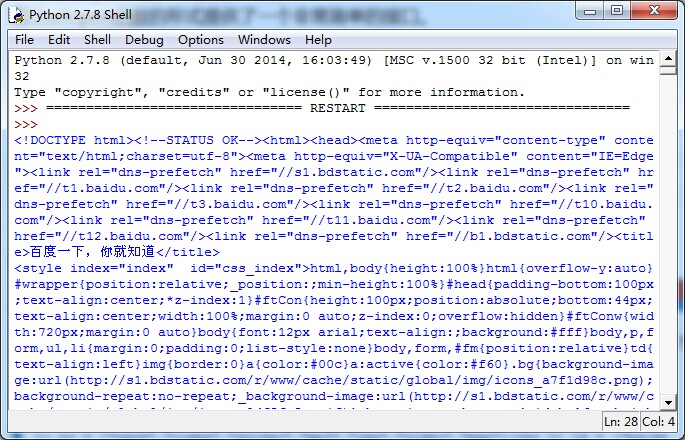
代码如下:
#coding:utf-8
import re,urllib2
def getHTML(url):
html=urllib2.urlopen(url)
html=html.read()
return html
if __name__=='__main__':
url='https://www.baidu.com'
#处理换行符以及空格
print getHTML(url).replace('\n','').replace('\t','').replace(' ','')
总结
以上所述是小编给大家介绍的python爬虫正则表达式之处理换行符,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!