yipeiwu_com6年前
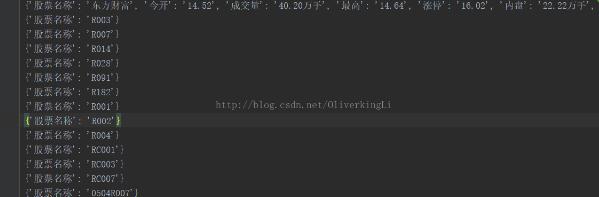
实例如下所示: import requests from bs4 import BeautifulSoup import traceback import re def getH...
yipeiwu_com6年前
多线程概述 多线程使得程序内部可以分出多个线程来做多件事情,充分利用CPU空闲时间,提升处理效率。python提供了两个模块来实现多线程thread 和threading ,thread...
yipeiwu_com6年前
urllib的基本用法 urllib库的基本组成 利用最简单的urlopen方法爬取网页html 利用Request方法构建headers模拟浏览器操作 error的异常操作 ur...
yipeiwu_com6年前
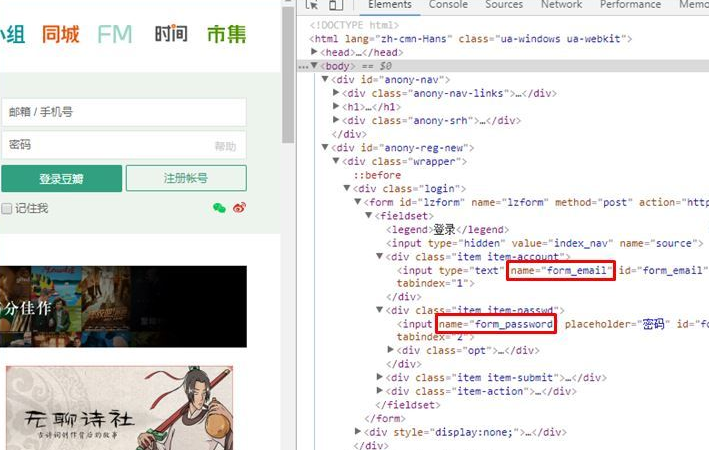
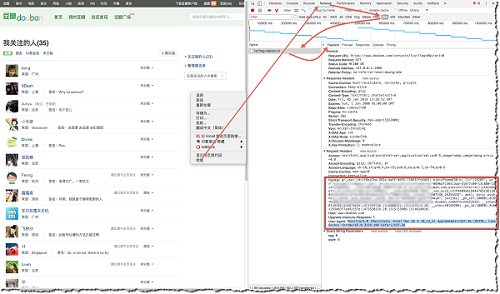
以豆瓣为例,访问https://www.douban.com/contacts/list 来查看自己关注的人,要登录才能查看。 如果用requests.get()方法获取这个http,没...
yipeiwu_com6年前
python的版本经过了python2.x和python3.x等版本,无论哪种版本,关于python爬虫相关的知识是融会贯通的,脚本之家关于爬虫这个方便整理过很多有价值的教程,小编通过本...
yipeiwu_com6年前
Queue Tornado的tornado.queue模块为基于协程的应用程序实现了一个异步生产者/消费者模式的队列。这与python标准库为多线程环境实现的queue模块类似。 一个协...
yipeiwu_com6年前
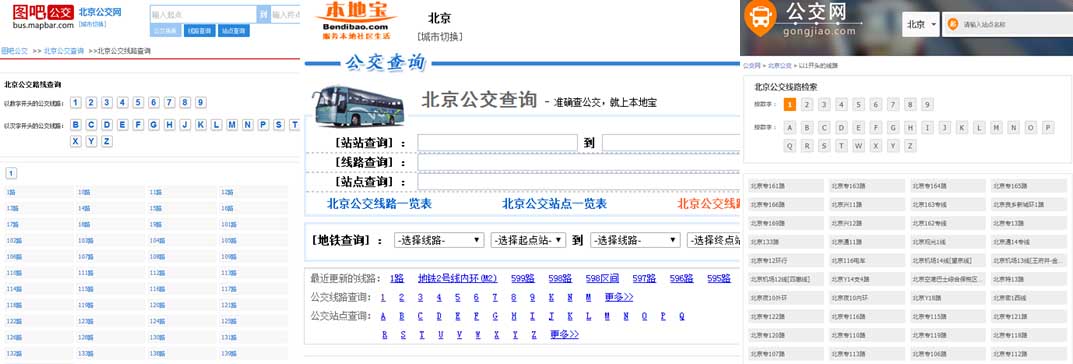
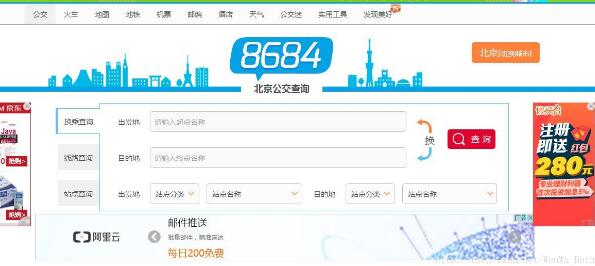
城市公交、地铁数据反映了城市的公共交通,研究该数据可以挖掘城市的交通结构、路网规划、公交选址等。但是,这类数据往往掌握在特定部门中,很难获取。互联网地图上有大量的信息,包含公交、地铁等数...
yipeiwu_com6年前
爬取的站点:http://beijing.8684.cn/ (1)环境配置,直接上代码: # -*- coding: utf-8 -*- import requests ##导入r...
yipeiwu_com6年前
目标 嗯,我们知道搜索或浏览网站时会有很多精美、漂亮的图片。 我们下载的时候,得鼠标一个个下载,而且还翻页。 那么,有没有一种方法,可以使用非人工方式自动识别并下载图片。美美哒。 那么请...
yipeiwu_com6年前
上篇关于爬虫的文章,我们讲解了如何运用Python的requests及BeautifuiSoup模块来完成静态网页的爬取,总结过程,网页爬虫本质就两步: 1、设置请求参数(url,hea...