Python爬虫_城市公交、地铁站点和线路数据采集实例
城市公交、地铁数据反映了城市的公共交通,研究该数据可以挖掘城市的交通结构、路网规划、公交选址等。但是,这类数据往往掌握在特定部门中,很难获取。互联网地图上有大量的信息,包含公交、地铁等数据,解析其数据反馈方式,可以通过Python爬虫采集。闲言少叙,接下来将详细介绍如何使用Python爬虫爬取城市公交、地铁站点和数据。
首先,爬取研究城市的所有公交和地铁线路名称,即XX路,地铁X号线。可以通过图吧公交、公交网、8684、本地宝等网站获取,该类网站提供了按数字和字母划分类别的公交线路名称。Python写个简单的爬虫就能采集,可参看WenWu_Both的文章,博主详细介绍了如何利用python爬取8684上某城市所有的公交站点数据。该博主采集了站点详细的信息,包括,但是缺少了公交站点的坐标、公交线路坐标数据。这就让人抓狂了,没有空间坐标怎么落图,怎么分析,所以,本文重点介绍的是站点坐标、线路的获取。
以图吧公交为例,点击某一公交后,出现该路公交的详细站点信息和地图信息。博主顿感兴奋,觉得马上就要成功了,各种抓包,发现并不能解析。可能博主技术所限,如有大神能从中抓到站点和线路的坐标信息,请不宁赐教。这TM就让人绝望了啊,到嘴的肥肉吃不了。
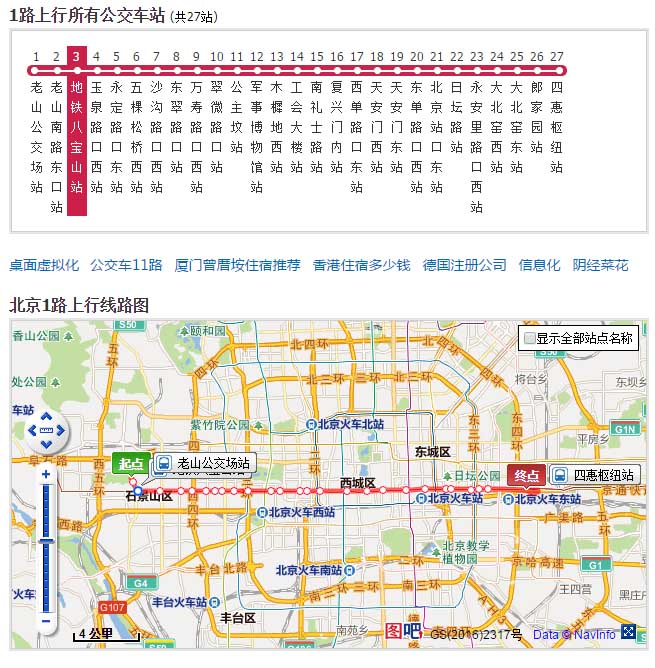
天无绝人之路,尝试找找某地图的API,发现可以调用,通过解析,能够找到该数据的后台地址。熟悉前端的可以试试,博主前端也就只会个hello world,不献丑了。这是一种思路,实践证明是可以的。
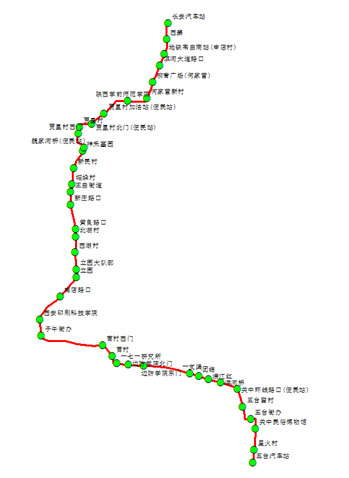
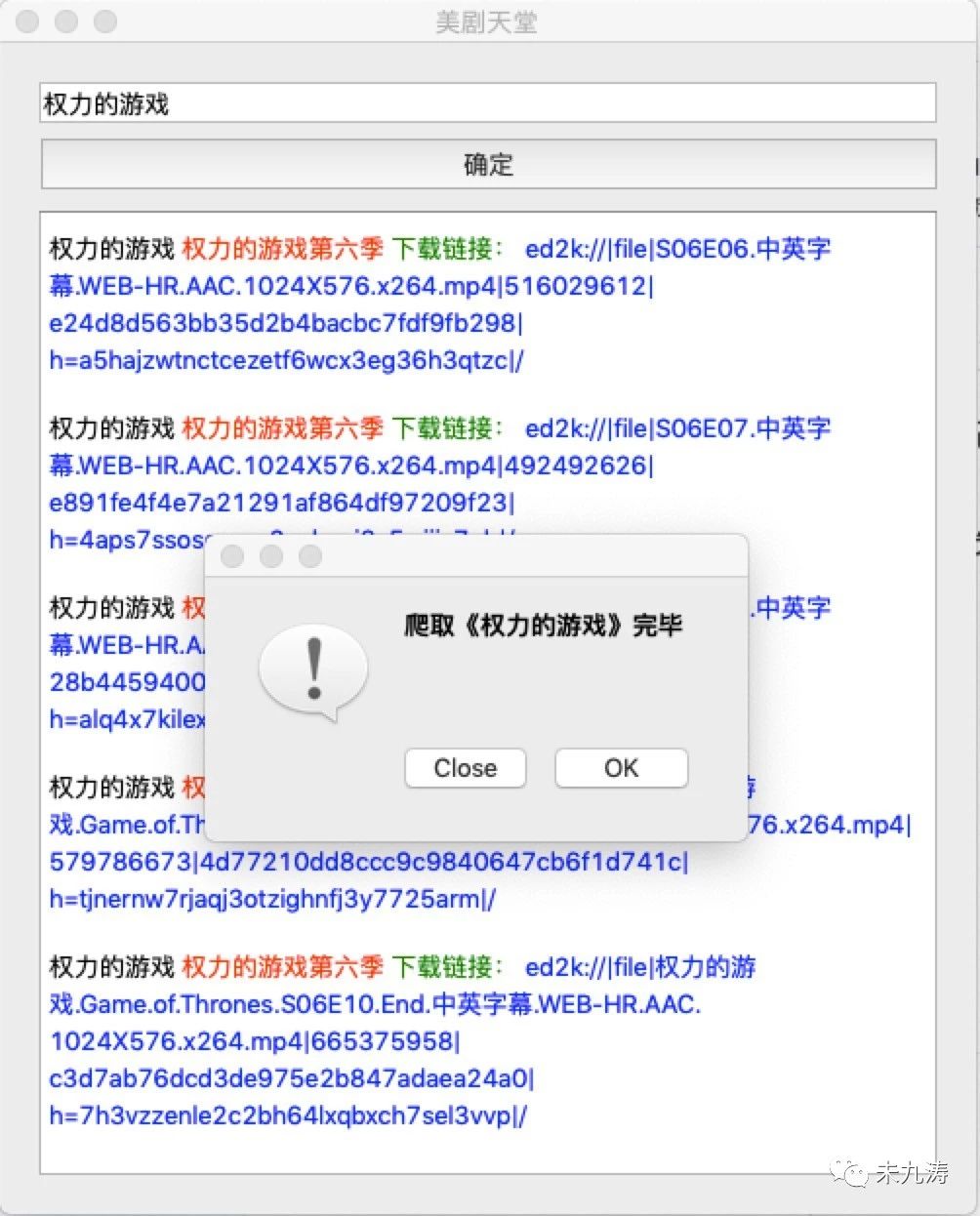
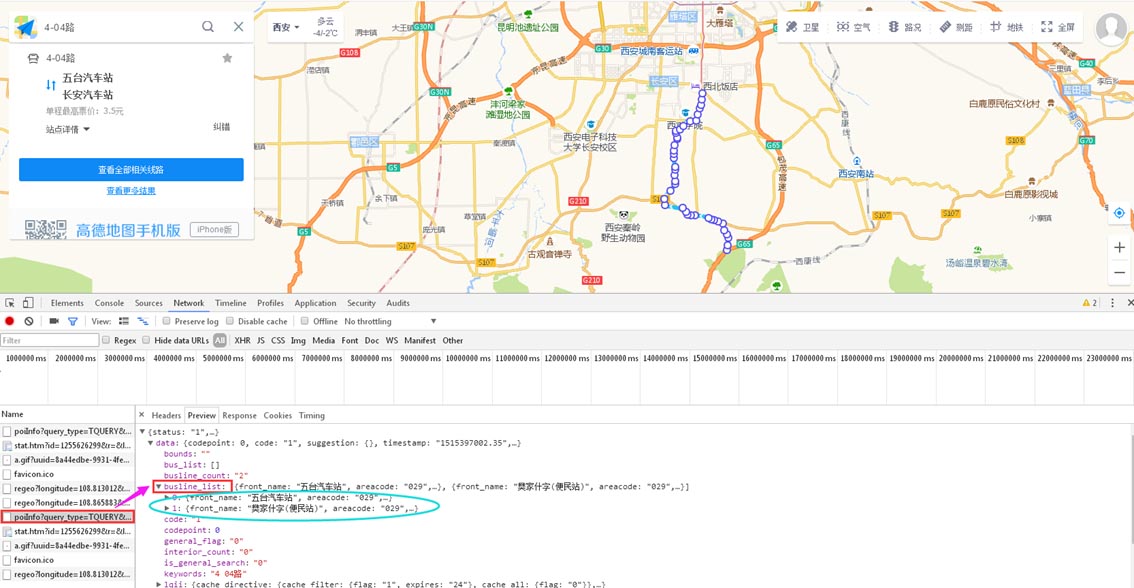
地图API可以,那么通过地图抓包呢?打开某图主页,直接输入某市公交名称,通过抓包,成功找到站点和线路信息。具体抓包信息如下图所示,busline_list中详细列出了站点和线路的信息,其中有两条,是同一趟公交不同方向的数据,略有差别,需注意。找到入口过后,接下来爬虫就要大显身手了。
主要爬取代码如下,其实也很简单,主函数如下。首先需要构建传入的参数,主要的包括路线名称,城市编码,地理范围,缩放尺度。地理范围可以通过坐标拾取器获取,参数经url编码后,发送请求,判断返回数据是否符合要求(注:可能该线路地图上停运或不存在,也可能是访问速度过快,反爬虫机制需要人工验证,博主爬取的时候碰到过,所以后面设置了随机休眠)。接下来,就是解析json数据了。代码中的extratStations和extractLine,就是提取需要的字段,怎么样,是不是很简单。最后,就是保存了,站点和路线分别存储。
def main():
df = pd.read_excel("线路名称.xlsx",)
BaseUrl = "https://ditu.amap.com/service/poiInfo?query_type=TQUERY&pagesize=20&pagenum=1&qii=true&cluster_state=5&need_utd=true&utd_sceneid=1000&div=PC1000&addr_poi_merge=true&is_classify=true&"
for bus in df[u"线路"]:
params = {
'keywords':'11路',
'zoom': '11',
'city':'610100',
'geoobj':'107.623|33.696|109.817|34.745'
}
print(bus)
paramMerge = urllib.parse.urlencode(params)
#print(paramMerge)
targetUrl = BaseUrl + paramMerge
stationFile = "./busStation/" + bus + ".csv"
lineFile = "./busLine/" + bus + ".csv"
req = urllib.request.Request(targetUrl)
res = urllib.request.urlopen(req)
content = res.read()
jsonData = json.loads(content)
if (jsonData["data"]["message"]) and jsonData["data"]["busline_list"]:
busList = jsonData["data"]["busline_list"] ##busline 列表
busListSlt = busList[0] ## busList共包含两条线,方向不同的同一趟公交,任选一趟爬取
busStations = extratStations(busListSlt)
busLine = extractLine(busListSlt)
writeStation(busStations, stationFile)
writeLine(busLine, lineFile)
sleep(random.random() * random.randint(0,7) + random.randint(0,5)) #设置随机休眠
else:
continue
附上博主的解析函数:
def extratStations(busListSlt):
busName = busListSlt["name"]
stationSet = []
stations = busListSlt["stations"]
for bs in stations:
tmp = []
tmp.append(bs["station_id"])
tmp.append(busName)
tmp.append(bs["name"])
cor = bs["xy_coords"].split(";")
tmp.append(cor[0])
tmp.append(cor[1])
wgs84cor1 = gcj02towgs84(float(cor[0]),float(cor[1]))
tmp.append(wgs84cor1[0])
tmp.append(wgs84cor1[1])
stationSet.append(tmp)
return stationSet
def extractLine(busListSlt):
## busList共包含两条线,备注名称
keyName = busListSlt["key_name"]
busName = busListSlt["name"]
fromName = busListSlt["front_name"]
toName = busListSlt["terminal_name"]
lineSet = []
Xstr = busListSlt["xs"]
Ystr = busListSlt["ys"]
Xset = Xstr.split(",")
Yset = Ystr.split(",")
length = len(Xset)
for i in range(length):
tmp = []
tmp.append(keyName)
tmp.append(busName)
tmp.append(fromName)
tmp.append(toName)
tmp.append(Xset[i])
tmp.append(Yset[i])
wgs84cor2 = gcj02towgs84(float(Xset[i]),float(Yset[i]))
tmp.append(wgs84cor2[0])
tmp.append(wgs84cor2[1])
lineSet.append(tmp)
return lineSet
爬虫采集原始数据如下:
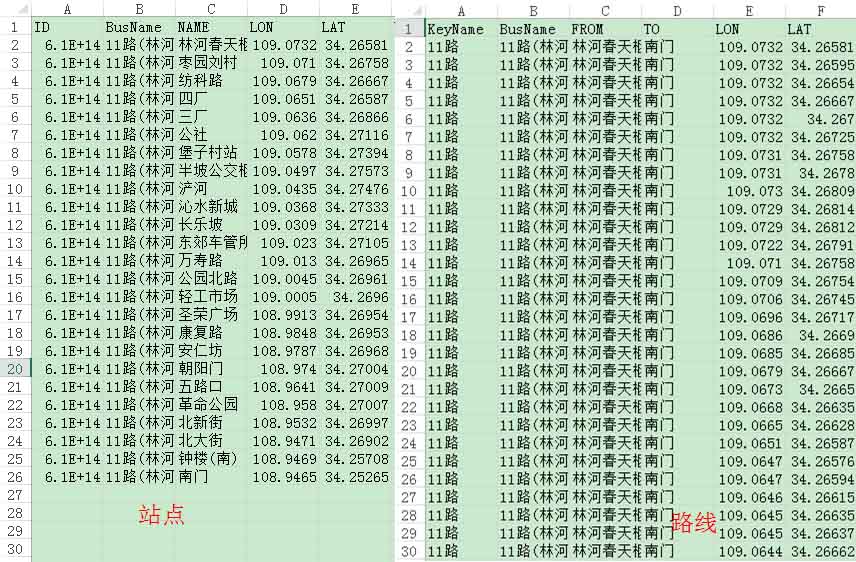
以下是某一条公交站点和线路的处理后的数据展示。由于不同的地图商采用不同的坐标系,会有不同程度的偏差,需要坐标纠偏。下一步,博主将详细介绍如何批量将这些站点和坐标进行坐标纠正和矢量化。