Python爬虫中urllib库的进阶学习
urllib的基本用法
urllib库的基本组成
利用最简单的urlopen方法爬取网页html
利用Request方法构建headers模拟浏览器操作
error的异常操作
urllib库除了以上基础的用法外,还有很多高级的功能,可以更加灵活的适用在爬虫应用中,比如:
使用HTTP的POST请求方法向服务器提交数据实现用户登录
使用代理IP解决防止反爬
设置超时提高爬虫效率
解析URL的方法
本次将会对这些内容进行详细的分析和讲解。
POST请求
POST是HTTP协议的请求方法之一,也是比较常用到的一种方法,用于向服务器提交数据。博主先介绍进行post请求的一些准备工作,然后举一个例子,对其使用以及更深层概念进行详细的的剖析。
POST请求的准备工作
既然要提交信息给服务器,我们就需要知道信息往哪填,填什么,填写格式是什么?带这些问题,我们往下看。
同样提交用户登录信息(用户名和密码),不同网站可能需要的东西不一样,比如淘宝反爬机制较复杂,会有其它一大串的额外信息。这里,我们以豆瓣为例(相对简单),目标是弄清楚POST是如何使用的,复杂内容会在后续实战部分与大家继续分享。
抛出上面像淘宝一样需要的复杂信息,如果仅考虑用户名和密码的话,我们的准备工作其实就是要弄明白用户名和密码标签的属性name是什么,以下两种方法可以实现。
浏览器F12查看element获取
也可以通过抓包工具Fiddler获取。
废话不多说了,让我们看看到底如何找到name?
1. 浏览器F12
通过浏览器F12元素逐层查看到(我是用的Chrome),邮箱/手机号标签的name="form_email", 密码的标签name="form_email",如下图红框所示。
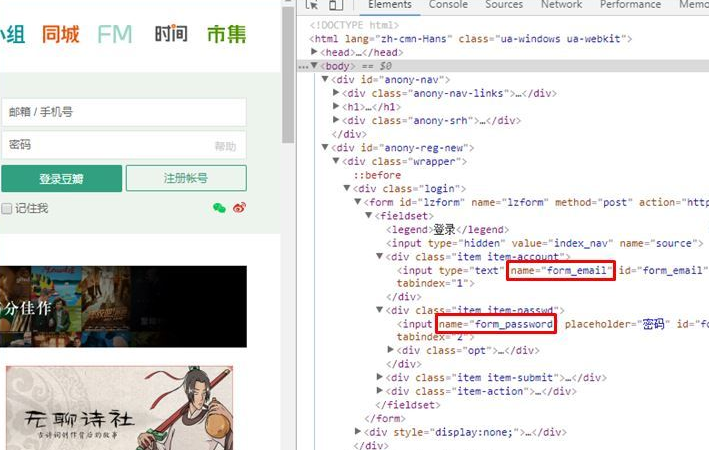
但要说明的是,两个标签的name名称并不是固定的,上面查看的name名称只是豆瓣网站定义的,不代表所有。其它的网站可能有会有不同的名称,比如name="username", name="password"之类的。因此,针对不同网站的登录,需要每次查看name是什么。
2. 通过fiddler抓包工具
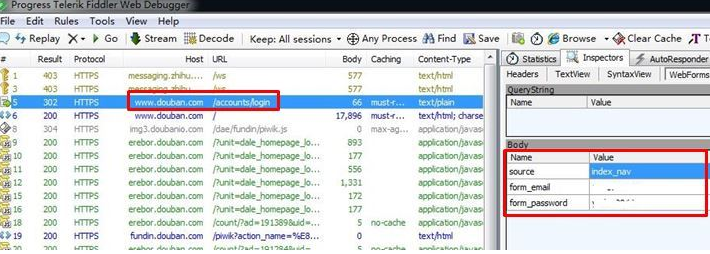
博主推荐使用fiddler工具,非常好用。爬虫本身就是模拟浏览器工作,我们只需要知道浏览器是怎么工作的就可以了。
fiddler会帮助我们抓取浏览器POST请求的所有内容,这样我们得到了浏览器POST的信息,把它填到爬虫程序里模拟浏览器操作就OK了。另外,也可以通过fiddler抓到浏览器请求的headers,非常方便。
安装fiddler的小伙伴们注意:fiddler证书问题的坑(无法抓取HTTPs包),可以通过Tools —> Options —>HTTPS里面打勾Decrypt HTTPS traffic修改证书来解决。否则会一直显示抓取 Tunnel 信息包...
好了,完成了准备工作,我们直接上一段代码理解下。
POST请求的使用
# coding: utf-8
import urllib.request
import urllib.error
import urllib.parse
# headers 信息,从fiddler上或你的浏览器上可复制下来
headers = {'Accept': 'text/html,application/xhtml+xml,
application/xml;q=0.9,image/webp,image/apng,
*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3;
Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko)Chrome/48.0
.2564.48 Safari/537.36'
}
# POST请求的信息,填写你的用户名和密码
value = {'source': 'index_nav',
'form_password': 'your password',
'form_email': 'your username'
}
try:
data = urllib.parse.urlencode(value).encode('utf8')
response = urllib.request.Request(
'https://www.douban.com/', data=data, headers=headers)
html = urllib.request.urlopen(response)
result = html.read().decode('utf8')
print(result)
except urllib.error.URLError as e:
if hasattr(e, 'reason'):
print('错误原因是' + str(e.reason))
except urllib.error.HTTPError as e:
if hasattr(e, 'code'):
print('错误编码是' + str(e.code))
else:
print('请求成功通过。')
运行结果:
<!DOCTYPE HTML>
<html lang="zh-cmn-Hans" class="ua-windows ua-webkit">
<head>
<meta charset="UTF-8">
<meta name="description" content="提供图书、电影、音乐唱片的
推荐、评论和价格比较,以及城市独特的文化生活。">
.....
window.attachEvent('onload', _ga_init);
}
</script>
</body>
</html>
注意:复制header的时候请去掉 这一项'Accept-Encoding':' gzip, deflate, 否则会提示decode的错误。
POST请求代码分析
我们来分析一下上面的代码,与urllib库request的使用基本一致,urllib库request的基本用法可参考上篇文章Python从零学爬虫,这里多出了post的data参数和一些解析的内容,着重讲解一下。
data = urllib.parse.urlencode(value).encode('utf8')
这句的意思是利用了urllib库的parse来对post内容解析,为什么要解析呢?
这是因为post内容需要进行一定的编码格式处理后才能发送,而编码的规则需要遵从RFC标准,百度了一下RFC定义,供大家参考:
Request ForComments(RFC),是一系列以编号排定的文件。文件收集了有关互联网相关信息,以及UNIX和互联网社区的软件文件。目前RFC文件是由InternetSociety(ISOC)赞助发行。基本的互联网通信协议都有在RFC文件内详细说明。RFC文件还额外加入许多的论题在标准内,例如对于互联网新开发的协议及发展中所有的记录。因此几乎所有的互联网标准都有收录在RFC文件之中。
而parse的urlencode方法是将一个字典或者有顺序的二元素元组转换成为URL的查询字符串(说白了就是按照RFC标准转换了一下格式)。然后再将转换好的字符串按UTF-8的编码转换成为二进制格式才能使用。
注:以上是在Python3.x环境下完成,Python3.x中编码解码规则为 byte—>string—>byte的模式,其中byte—>string为解码,string—>byte为编码
代理IP
代理IP的使用
为什么要使用代理IP?因为各种反爬机制会检测同一IP爬取网页的频率速度,如果速度过快,就会被认定为机器人封掉你的IP。但是速度过慢又会影响爬取的速度,因此,我们将使用代理IP取代我们自己的IP,这样不断更换新的IP地址就可以达到快速爬取网页而降低被检测为机器人的目的了。
同样利用urllib的request就可以完成代理IP的使用,但是与之前用到的urlopen不同,我们需要自己创建订制化的opener。什么意思呢?
urlopen就好像是opener的通用版本,当我们需要特殊功能(例如代理IP)的时候,urlopen满足不了我们的需求,我们就不得不自己定义并创建特殊的opener了。
request里面正好有处理各种功能的处理器方法,如下:
ProxyHandler, UnknownHandler, HTTPHandler, HTTPDefaultErrorHandler, HTTPRedirectHandler, FTPHandler, FileHandler, HTTPErrorProcessor, DataHandler
我们要用的是第一个ProxyHandler来处理代理问题。
让我们看一段代码如何使用。
# coding:utf-8
import urllib.request
import urllib.error
import urllib.parse
# headers信息,从fiddler上或浏览器上可复制下来
headers = {'Accept': 'text/html,application/xhtml+xml,
application/xml;q=0.9,image/webp,image/apng,
*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3;
Win64;
x64) AppleWebKit/537.36 (KHTML,
like Gecko)Chrome/48.0.2564.48
Safari/537.36'
}
# POST请求的信息
value = {'source': 'index_nav',
'form_password': 'your password',
'form_email': 'your username'
}
# 代理IP信息为字典格式,key为'http',value为'代理ip:端口号'
proxy = {'http': '115.193.101.21:61234'}
try:
data = urllib.parse.urlencode(value).encode('utf8')
response = urllib.request.Request(
'https://www.douban.com/', data=data, headers=headers)
# 使用ProxyHandler方法生成处理器对象
proxy_handler = urllib.request.ProxyHandler(proxy)
# 创建代理IP的opener实例
opener = urllib.request.build_opener(proxy_handler)
# 将设置好的post信息和headers的response作为参数
html = opener.open(response)
result = html.read().decode('utf8')
print(result)
except urllib.error.URLError as e:
if hasattr(e, 'reason'):
print('错误原因是' + str(e.reason))
except urllib.error.HTTPError as e:
if hasattr(e, 'code'):
print('错误编码是' + str(e.code))
else:
print('请求成功通过。')
在上面post请求代码的基础上,用自己创建的opener替换urlopen即可完成代理IP的操作,代理ip可以到一些免费的代理IP网站上查找。
以上就是我们整理的全部内容,感谢你对【听图阁-专注于Python设计】的支持。