yipeiwu_com6年前
关于cookie和session估计很多程序员面试的时候都会被问到,这两个概念在写web以及爬虫中都会涉及,并且两者可能很多人直接回答也不好说的特别清楚,所以整理这样一篇文章,也帮助自己...
yipeiwu_com6年前
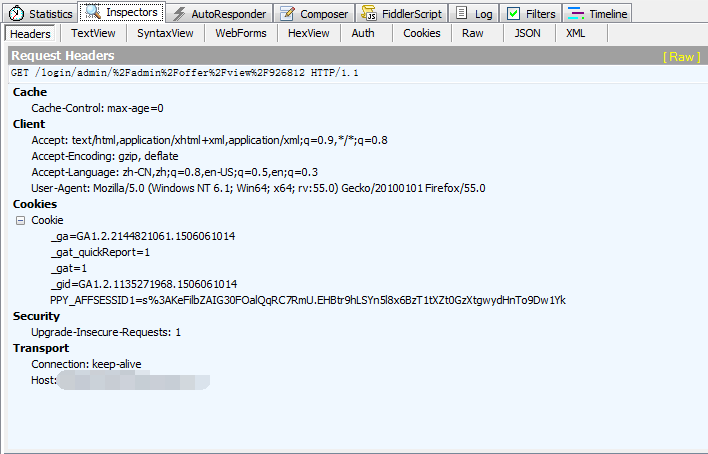
前言: 什么是cookie? Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)。 比如说有些网站需要登录后才能访问某个...
yipeiwu_com6年前
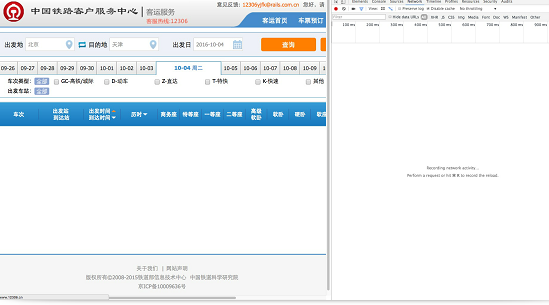
本文思路主要来源于实验楼的教程,但是一些具体的一些细节是我自己发现的,比如哪里获得站点对应的3位英文编号,怎么获得这个查询的url 本文用到的库主要有requests(获取url的内容)...
yipeiwu_com6年前
前段时间自学了一段时间的Python,想着浓一点项目来练练手。看着大佬们一说就是爬了100W+的数据就非常的羡慕,不过对于我这种初学者来说,也就爬一爬图片。 我相信很多人的第一个...
yipeiwu_com6年前
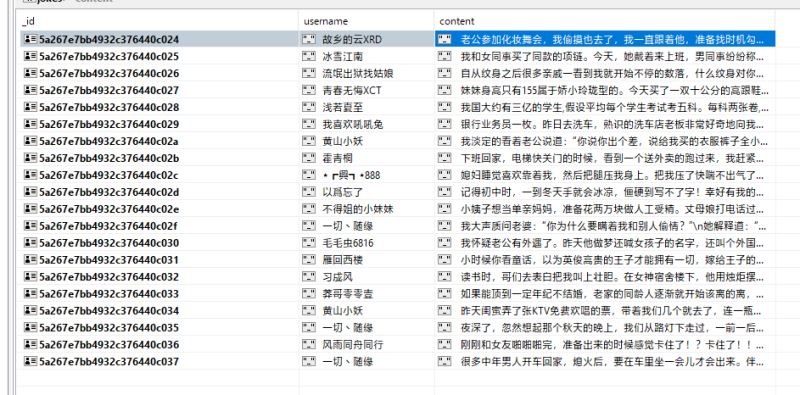
前一篇文章介绍了很多关于scrapy的进阶知识,不过说归说,只有在实际应用中才能真正用到这些知识。所以这篇文章就来尝试利用scrapy爬取各种网站的数据。 爬取百思不得姐 首先一步一步来...
yipeiwu_com6年前
简单低级的爬虫速度快,伪装度低,如果没有反爬机制,它们可以很快的抓取大量数据,甚至因为请求过多,造成服务器不能正常工作。而伪装度高的爬虫爬取速度慢,对服务器造成的负担也相对较小。 爬虫与...
yipeiwu_com6年前
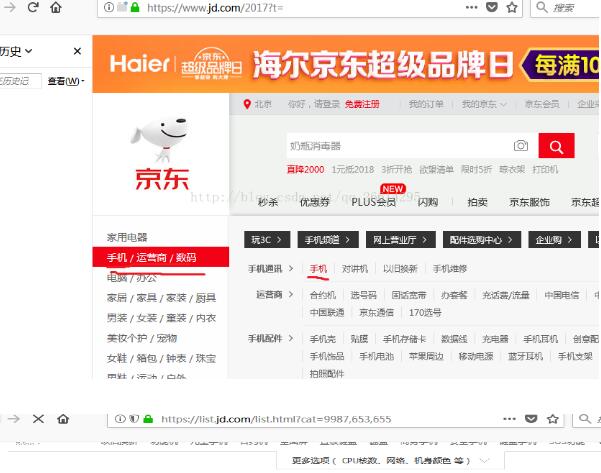
如题,首先当然是要打开京东的手机页面 因为要获取不同页面的所有手机图片,所以我们要跳转到不同页面观察页面地址的规律,这里观察第二页页面 由观察可以得到,第二页的链接地址很有可能是...
yipeiwu_com6年前
简介: 网络爬虫(又被称为网页蜘蛛),网络机器人,是一种按照一定的规则,自动地抓信息的程序或者脚本。假设互联网是一张很大的蜘蛛网,每个页面之间都通过超链接这根线相互连接,那么我们的爬虫小...
yipeiwu_com6年前
统计十篇新闻TF-IDF 统计TF-IDF词频,每篇文章的 top10 的高频词存储为 json 文件 TF-IDF TF-IDF(term frequency–inverse docu...
yipeiwu_com6年前
Python爬虫为什么受欢迎 如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工...