yipeiwu_com6年前
学用python也有3个多月了,用得最多的还是各类爬虫脚本:写过抓代理本机验证的脚本,写过在discuz论坛中自动登录自动发贴的脚本,写过自动收邮件的脚本,写过简单的验证码识别的脚本,本...
yipeiwu_com6年前
本文实例讲述了Python实现可获取网易页面所有文本信息的网易网络爬虫功能。分享给大家供大家参考,具体如下: #coding=utf-8 #---------------------...
yipeiwu_com6年前
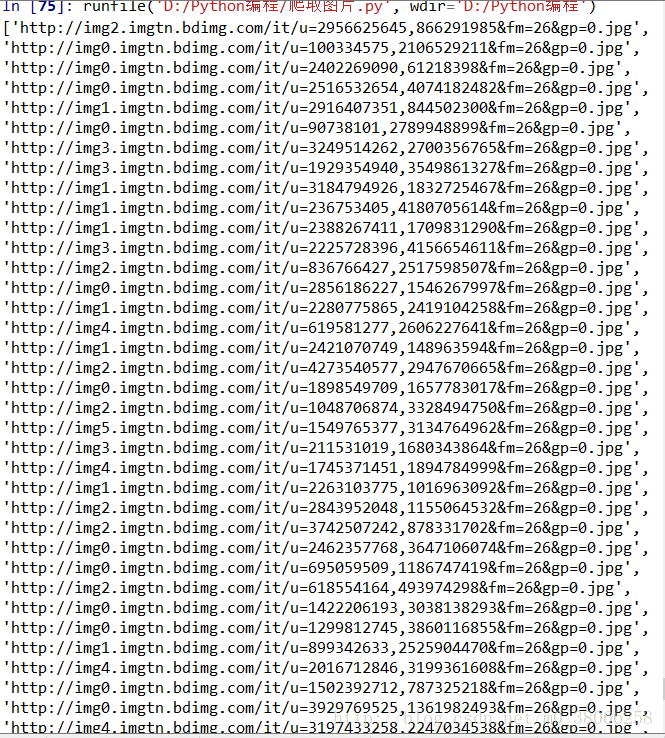
本文实例主要是实现爬取一个网页上的图片地址,具体如下。 读取一个网页的源代码: import urllib.request def getHtml(url): html=urll...
yipeiwu_com6年前
本文实例主要实现的是使用urllib和BeautifulSoup爬取维基百科的词条,具体如下。 简洁代码: #引入开发包 from urllib.request import url...
yipeiwu_com6年前
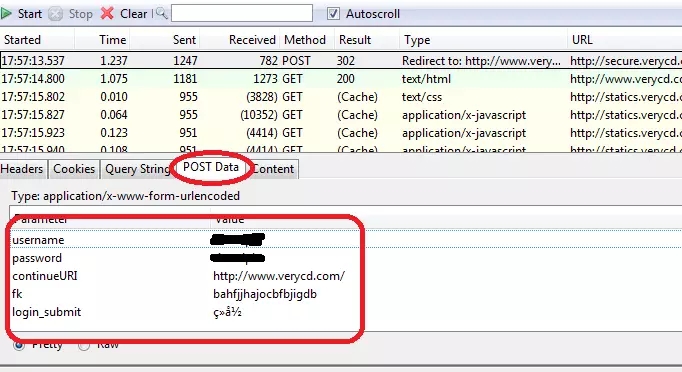
直接入正题---Python selenium自动控制浏览器对网页的数据进行抓取,其中包含按钮点击、跳转页面、搜索框的输入、页面的价值数据存储、mongodb自动id标识等等等。 1、首...
yipeiwu_com6年前
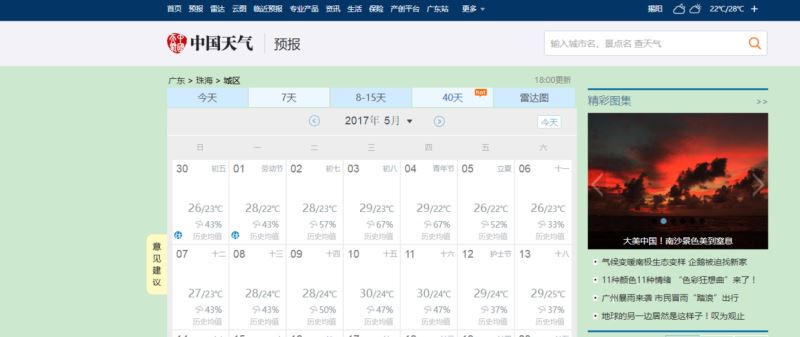
本文研究的主要是Python爬虫天气预报的相关内容,具体介绍如下。 这次要爬的站点是这个:http://www.weather.com.cn/forecast/ 要求是把你所在城市过去...
yipeiwu_com6年前
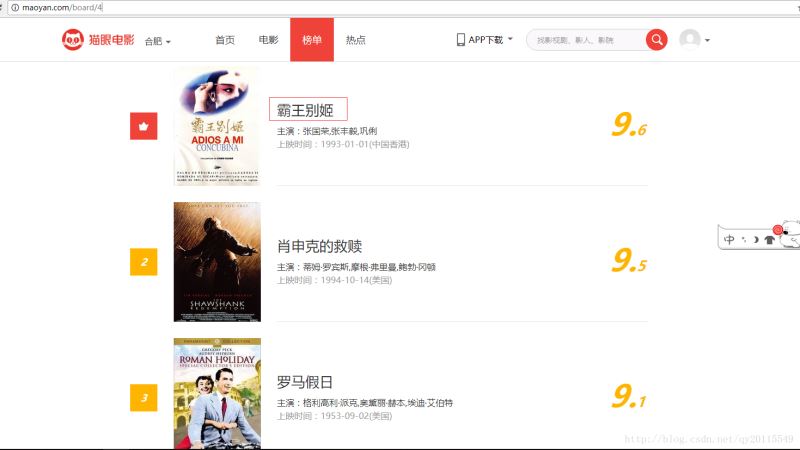
本文研究的主要是Python使用requests及BeautifulSoup构建一个网络爬虫,具体步骤如下。 功能说明 在Python下面可使用requests模块请求某个url获取响应...
yipeiwu_com6年前
今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站——拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大...
yipeiwu_com6年前
本文主要通过实例介绍了scrapy框架的使用,分享了两个例子,爬豆瓣文本例程 douban 和图片例程 douban_imgs ,具体如下。 例程1: douban 目录树 doub...
yipeiwu_com6年前
本节课介绍了scrapy的爬虫框架,重点说了scrapy组件spider。 spider的几种爬取方式: 爬取1页内容 按照给定列表拼出链接爬取多页 找到‘下一页'标签进行...