使用python爬虫实现网络股票信息爬取的demo
实例如下所示:
import requests
from bs4 import BeautifulSoup
import traceback
import re
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def getStockList(lst, stockURL):
html = getHTMLText(stockURL)
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue
def getStockInfo(lst, stockURL, fpath):
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html=="":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div',attrs={'class':'stock-bets'})
name = stockInfo.find_all(attrs={'class':'bets-name'})[0]
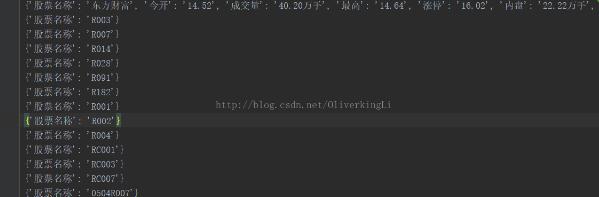
infoDict.update({'股票名称': name.text.split()[0]})
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
with open(fpath, 'a', encoding='utf-8') as f:
f.write( str(infoDict) + '\n' )
except:
traceback.print_exc()
continue
def main():
stock_list_url = 'http://quote.eastmoney.com/stocklist.html'
stock_info_url = 'https://gupiao.baidu.com/stock/'
output_file = 'D:/BaiduStockInfo.txt'
slist=[]
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file)
main()
优化并且加入进度条显示
import requests
from bs4 import BeautifulSoup
import traceback
import re
def getHTMLText(url, code="utf-8"):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = code
return r.text
except:
return ""
def getStockList(lst, stockURL):
html = getHTMLText(stockURL, "GB2312")
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue
def getStockInfo(lst, stockURL, fpath):
count = 0
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html == "":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div', attrs={'class': 'stock-bets'})
name = stockInfo.find_all(attrs={'class': 'bets-name'})[0]
infoDict.update({'股票名称': name.text.split()[0]})
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(infoDict) + '\n')
count = count + 1
print("\r当前进度: {:.2f}%".format(count * 100 / len(lst)), end="")
except:
count = count + 1
print("\r当前进度: {:.2f}%".format(count * 100 / len(lst)), end="")
continue
def main():
stock_list_url = 'http://quote.eastmoney.com/stocklist.html'
stock_info_url = 'https://gupiao.baidu.com/stock/'
output_file = 'BaiduStockInfo.txt'
slist = []
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file)
main()

以上这篇使用python爬虫实现网络股票信息爬取的demo就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。