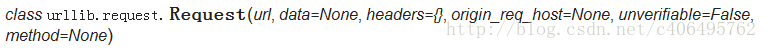yipeiwu_com6年前
本文介绍了python爬虫之BeautifulSoup 使用select方法详解 ,分享给大家。具体如下: <html><head><title>...
yipeiwu_com6年前
分享点干货!!! Python数据抓取分析 编程模块:requests,lxml,pymongo,time,BeautifulSoup 首先获取所有产品的分类网址: def s...
yipeiwu_com6年前
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。 下面有一个示例代码,分享给大家: #...
yipeiwu_com6年前
众所周知,python是写爬虫的利器,今天作者用python写一个小爬虫爬下一个段子网站的众多段子。 目标段子网站为“http://ishuo.cn/”,我们先分析其下段子的所在子页的u...
yipeiwu_com6年前
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队、CBA明星、花边新闻、球鞋美女等等,如果一张张右键另存为的话真是手都点...
yipeiwu_com6年前
题记:早已听闻python爬虫框架的大名。近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享。有表述不当之处,望大神们斧正。 一、初窥Scrapy Scrapy是一个为了爬...
yipeiwu_com6年前
1.scrapy基本了解 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取...
yipeiwu_com6年前
有的时候,我们本来写得好好的爬虫代码,之前还运行得Ok, 一下子突然报错了。 报错信息如下: Http 800 Internal internet error 这是因为你的对象网站设置了...
yipeiwu_com6年前
本文介绍了Python3网络爬虫之使用User Agent和代理IP隐藏身份,分享给大家,具体如下: 运行平台:Windows Python版本:Python3.x IDE...
yipeiwu_com6年前
Redis通常被认为是一种持久化的存储器关键字-值型存储,可以用于几台机子之间的数据共享平台。 连接数据库 注意:假设现有几台在同一局域网内的机器分别为Master和几个Slaver...