Python探索之爬取电商售卖信息代码示例
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。
下面有一个示例代码,分享给大家:
#! /usr/bin/env python
#
encoding = 'utf-8'#
Filename: spider_58center_sth.py
from bs4
import BeautifulSoup
import time
import requests
url_58 = 'http://nj.58.com/?PGTID=0d000000-0000-0c5c-ffba-71f8f3f7039e&ClickID=1'
''
'
用于爬取电商售卖信息: 例为58同城电脑售卖信息 ''
'
def get_url_list(url):
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text, 'lxml')
url = soup.select('td.t > a[class="t"]')
url_list = ''
for link in url:
link_n = link.get('href')
if 'zhuanzhuan' in link_n:
pass
else :
if 'jump' in link_n:
pass
else :
url_list = url_list + '\n' + link_n
print('url_list: %s' % url_list)
return url_list# 分类获取目标信息
def get_url_info():
url_list = get_url_list(url_58)
for url in url_list.split():
time.sleep(1)
web_datas = requests.get(url)
soup = BeautifulSoup(web_datas.text, 'lxml')
type = soup.select('#head > div.breadCrumb.f12 > span:nth-of-type(3) > a')
title = soup.select(' div.col_sub.mainTitle > h1')
date = soup.select('li.time')
price = soup.select('div.person_add_top.no_ident_top > div.per_ad_left > div.col_sub.summary > ul > '
'li:nth-of-type(1) > div.su_con > span.price.c_f50')
fineness = soup.select('div.col_sub.summary > u1 > li:nth-of-type(2) > div.su_con > span')
area = soup.select('div.col_sub.summary > u1 > li:nth-of-type(3) > div.su_con > span')
for typei, titlei, datei, pricei, finenessi, areai in zip(type, title, date, price, fineness, area): #做字典
data = {
'type': typei.get_text(),
'title': titlei.get_text(),
'date': datei.get_text(),
'price': pricei.get_text(),
'fineness': (finenessi.get_text()).strip(),
'area': list(areai.stripped_strings)
}
print(data)
get_url_info()
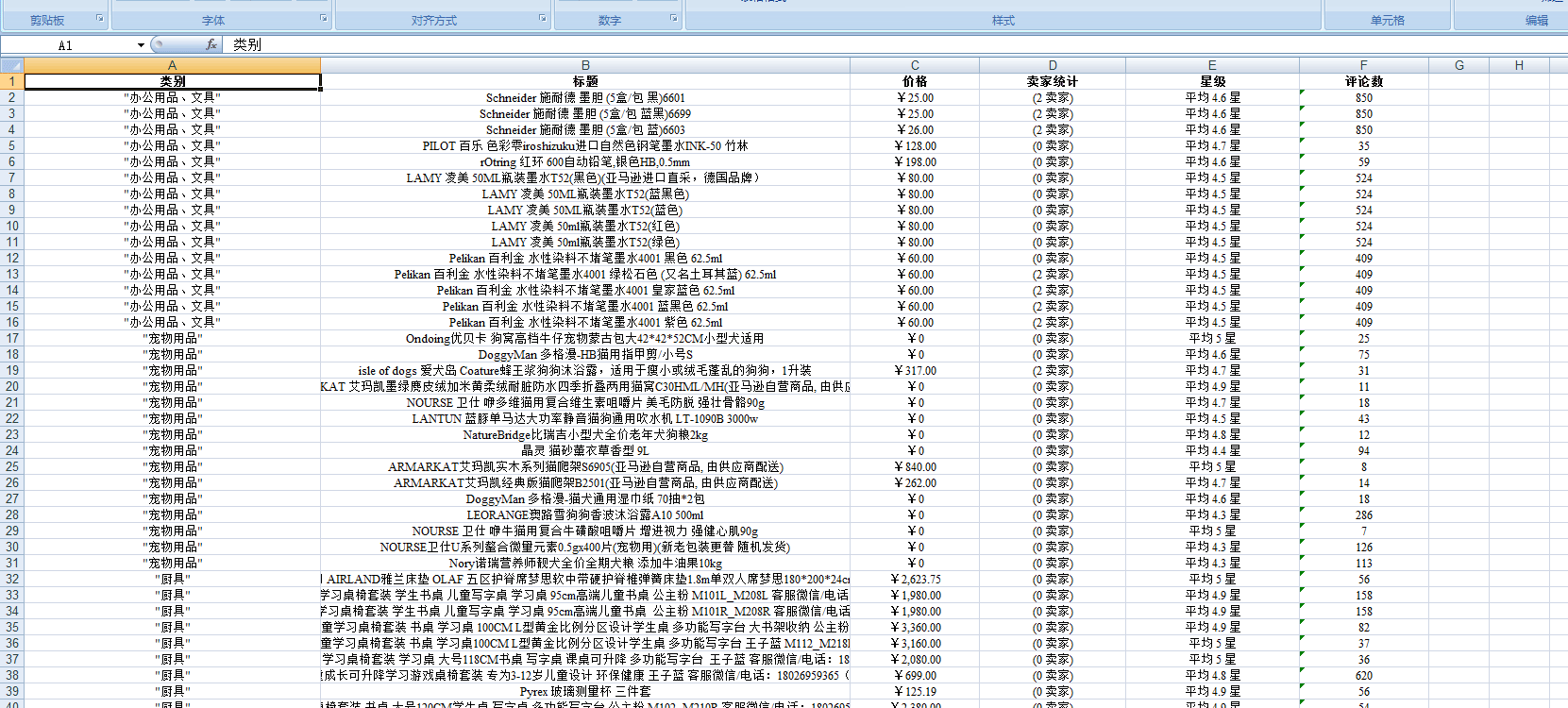
爬取商城商品售卖信息
总结
以上就是本文关于Python探索之爬取电商售卖信息代码示例的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站:Python探索之自定义实现线程池、Python探索之ModelForm代码详解等,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!