yipeiwu_com6年前
本文实例讲述了Python3.4编程实现简单抓取爬虫功能。分享给大家供大家参考,具体如下: import urllib.request import urllib.parse imp...
yipeiwu_com6年前
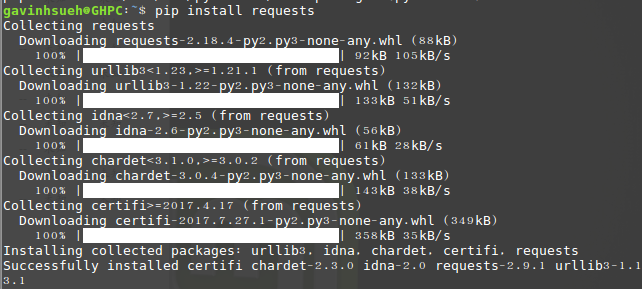
1.安装pip 我的个人桌面系统用的linuxmint,系统默认没有安装pip,考虑到后面安装requests模块使用pip,所以我这里第一步先安装pip。 $ sudo apt i...
yipeiwu_com6年前
本文实例讲述了Python开发中爬虫使用代理proxy抓取网页的方法。分享给大家供大家参考,具体如下: 代理类型(proxy):透明代理 匿名代理 混淆代理和高匿代理. 这里写一些pyt...
yipeiwu_com6年前
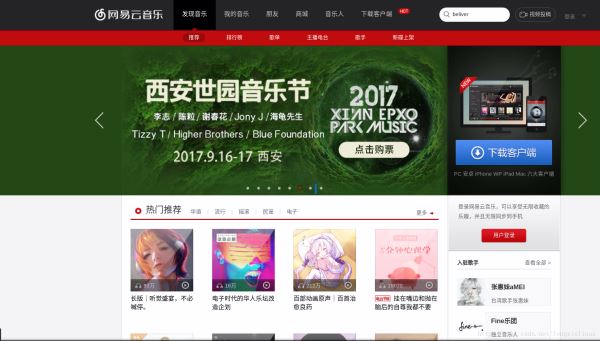
前言 之前刚刚入门python爬虫,有大概半个月时间没有写python了,都快遗忘了。于是准备写个简单的爬虫练练手,我觉得网易云音乐最优特色的就是其精准的歌曲推荐和独具特色的用户评论,于...
yipeiwu_com6年前
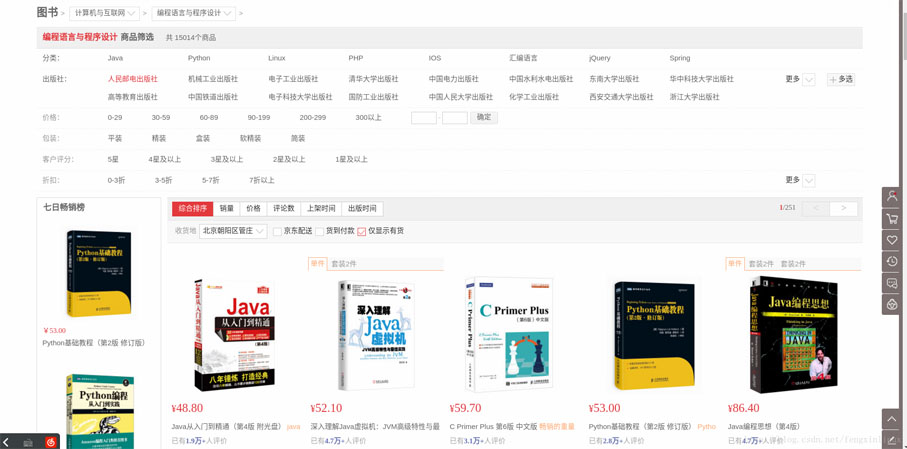
前言 最近工作中遇到一个需求,需要将京东上图书的图片下载下来,假如我们想把京东商城图书类的图片类商品图片全部下载到本地,通过手工复制粘贴将是一项非常庞大的工程,此时,可以用Python网...
yipeiwu_com6年前
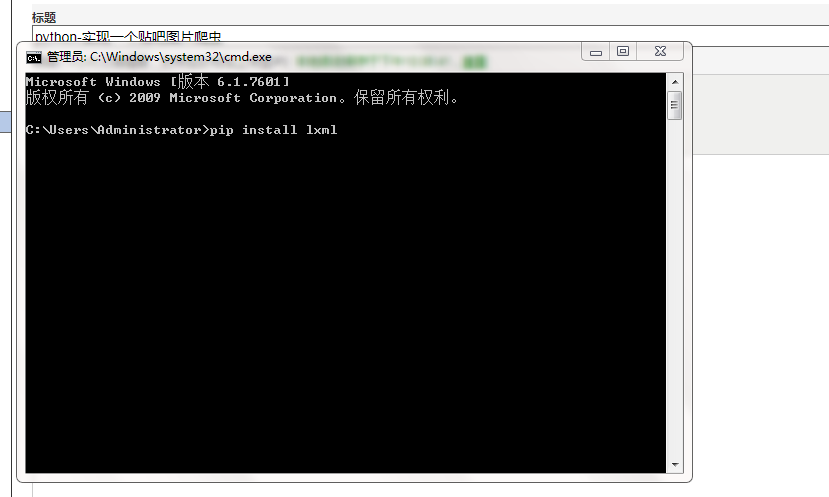
今天没事回家写了个贴吧图片下载程序,工具用的是PyCharm,这个工具很实用,开始用的Eclipse,但是再使用类库或者其它方便并不实用,所以最后下了个专业开发python程序的工具,开...
yipeiwu_com6年前
这篇博客是自己《数据挖掘与分析》课程讲到正则表达式爬虫的相关内容,主要简单介绍Python正则表达式爬虫,同时讲述常见的正则表达式分析方法,最后通过实例爬取作者的个人博客网站。希望这篇基...
yipeiwu_com6年前
此次遇到的是一个函数使用不熟练造成的问题,但有了分析工具后可以很快定位到问题(此处推荐一个非常棒的抓包工具fiddler) 正文如下: 在爬取某个app数据时(app上的数据...
yipeiwu_com6年前
学习爬虫有一段时间了,今天使用Scrapy框架将校花网的图片爬取到本地。Scrapy爬虫框架相对于使用requests库进行网页的爬取,拥有更高的性能。 Scrapy官方定义:Scrap...
yipeiwu_com6年前
问题描述 利用搜狗的微信搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地。 注意点 搜狗微信获取的地址为临时链接,具有时效性。 公众号为动态网页(JavaScript渲染),使用...