yipeiwu_com6年前
首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的。 (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作者,摘要,正文等信息 (3)存储到硬...
yipeiwu_com6年前
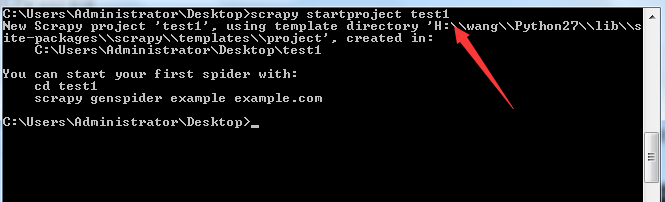
首先得有一个Scrapy项目,我在Desktop上新建一个Scrapy的项目叫test,在Desktop目录打开命令行,键入命令:scrapy startproject test1...
yipeiwu_com6年前
下载图片 下载图片有两种方式,一种是通过 Requests 模块发送 get 请求下载,另一种是使用 Scrapy 的 ImagesPipeline 图片管道类,这里主要讲后者。 安装...
yipeiwu_com6年前
实例如下所示: __author__ = 'Fred Zhao' import requests from bs4 import BeautifulSoup import os...
yipeiwu_com6年前
前言 Scrapy是一个非常好的抓取框架,它不仅提供了一些开箱可用的基础组建,还能够根据自己的需求,进行强大的自定义。本文主要给大家介绍了关于Python抓取框架Scrapy之页面提取的...
yipeiwu_com6年前
前言 没想到python是如此强大,令人着迷,以前看见图片总是一张一张复制粘贴,现在好了,学会python就可以用程序将一张张图片,保存下来。 最近看到斗鱼里的照片都不错,决定用最新学习...
yipeiwu_com6年前
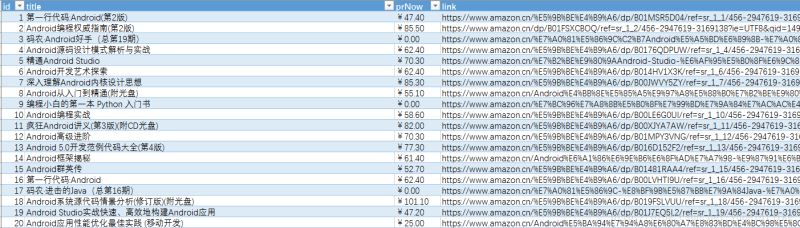
我有个需求就是抓取一些简单的书籍信息存储到mysql数据库,例如,封面图片,书名,类型,作者,简历,出版社,语种。 我比较之后,决定在亚马逊来实现我的需求。 我分析网站后发现,亚马逊有个...
yipeiwu_com6年前
注:1.本程序采用MSSQLserver数据库存储,请运行程序前手动修改程序开头处的数据库链接信息 2.需要bs4、requests、pymssql库支持 3.支持多线程 from...
yipeiwu_com6年前
本文主要分享关于python登录并爬取淘宝信息的相关代码,还是挺不错的,大家可以了解下。 #!/usr/bin/env python # -*- coding:utf-8 -*-...
yipeiwu_com6年前
本代码主要实现抓取大众点评网中关村附近的餐馆有哪些,具体如下: import urllib.request import re def fetchFood(url): #...