yipeiwu_com6年前
介绍 本篇文章主要介绍如何爬取麦子学院的课程信息(本爬虫仍是单线程爬虫),在开始介绍之前,先来看看结果示意图 怎么样,是不是已经跃跃欲试了?首先让我们打开麦子学院的网址,然后找到麦子学...
yipeiwu_com6年前
XPath 的安装以及使用 1 . XPath 的介绍 刚学过正则表达式,用的正顺手,现在就把正则表达式替换掉,使用 XPath,有人表示这太坑爹了,早知道刚上来就学习 XPath 多省...
yipeiwu_com6年前
早上起来闲来无事做,莫名其妙的就弹出了糗事百科的段子,转念一想既然你送上门来,那我就写个爬虫到你网站上爬一爬吧,一来当做练练手,二来也算找点乐子。 其实这两天也正在接触数据库的内容,可以...
yipeiwu_com6年前
在之前写过一篇使用python爬虫爬取电影天堂资源的文章,重点是如何解析页面和提高爬虫的效率。由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花...
yipeiwu_com6年前
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载。刚开始学习python希望可以获...
yipeiwu_com6年前
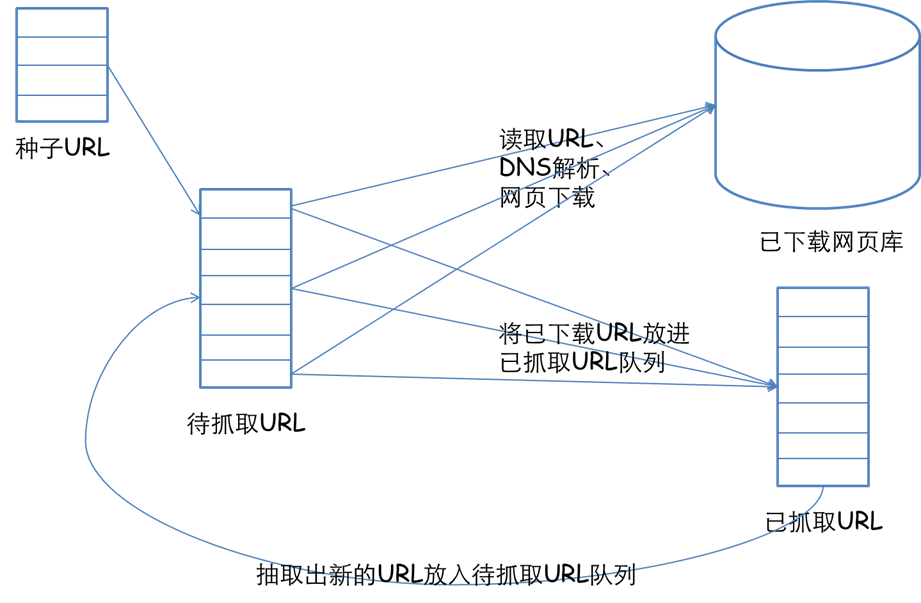
Python爬虫:一些常用的爬虫技巧总结 爬虫在开发过程中也有很多复用的过程,这里总结一下,以后也能省些事情。 1、基本抓取网页 get方法 import urllib2 url...
yipeiwu_com6年前
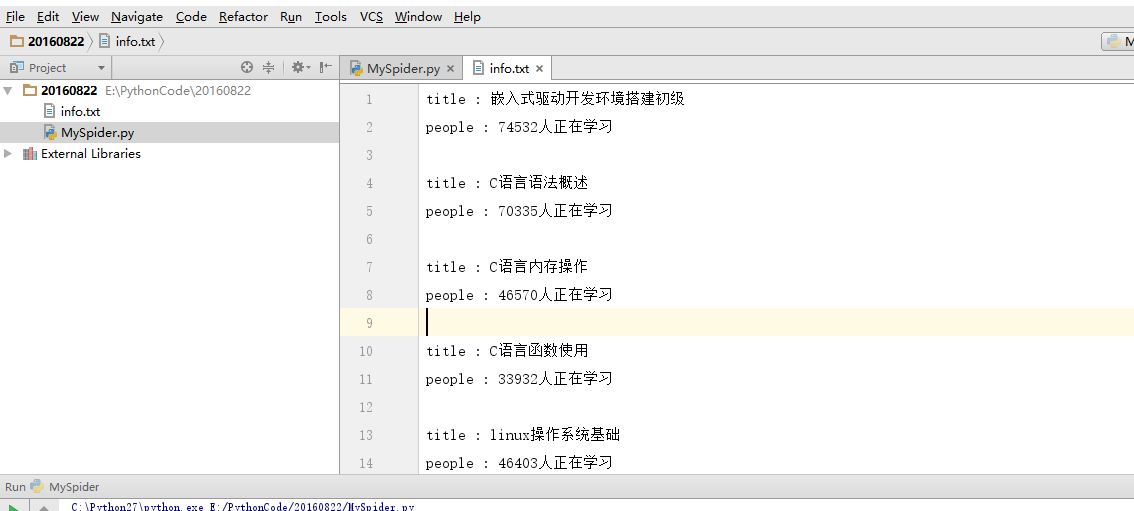
首先是准备工作 Python 2.7.11:下载python Pycharm:下载Pycharm 其中python2和python3目前同步发行,我这里使用的是python2作为环境。P...
yipeiwu_com6年前
实验室需要NUS-WIDE数据库中的原图,数据集的地址为http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm 由于这个...
yipeiwu_com6年前
python是支持多线程的,主要是通过thread和threading这两个模块来实现的。thread模块是比较底层的模块,threading模块是对thread做了一些包装的,可以更加...
yipeiwu_com6年前
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。 我们最常规的做法就是通过鼠标右键,选择另存为。但有...