Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的文章,重点是如何解析页面和提高爬虫的效率。由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了一下python模拟登陆,网上关于这部分的资料很多,很多demo都是登陆知乎的,原因是知乎的登陆比较简单,只需要post几个参数,保存cookie。而且还没有进行加密,很适合用来做教学。我也是是新手,一点点的摸索终于成功登陆上了知乎。就通过这篇文章分享一下学习这部分的心得,希望对那些和我一样的初学者有所帮助。
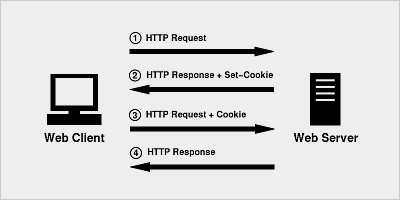
先来说一下,爬虫模拟登陆的基本原理吧,我也是刚开始接触对于一些深层次的东西也不是掌握的很清楚。首先比较重要的一个概念就是cookie,我们都知道HTTP是一种无状态的协议,也就是说当一个浏览器客户端向服务器提交一个request,服务器回应一个response后,他们之间的联系就中断了。这样就导致了这个客户端在向服务器发送请求时,服务器无法判别这两个客户端是不是一个了。这样肯定是不行的。这时cookie的作用就体现出来了。当客户端向服务器发送一个请求后,服务器会给它分配一个标识(cookie),并保存到客户端本地,当下次该客户端再次发送请求时连带着cookie一并发送给服务器,服务器一看到cookie,啊原来是你呀,这是你的东西,拿走吧。所以一个爬虫模拟登陆就是要要做到模拟一个浏览器客户端的行为,首先将你的基本登录信息发送给指定的url,服务器验证成功后会返回一个cookie,我们就利用这个cookie进行后续的爬取工作就行了。
我这里抓包用的就是chrome的开发者工具,不过你也可以使用Fiddler、Firebug等都可以,只不过作为一名前端er对chrome有一种特殊的喜爱之情。准备好工具接下来就要打开知乎的登陆页面并查看https://www.zhihu.com/#signin 我们可以很容易发现这个请求 发送的就是登录信息,当然我使用手机登陆的 用邮件登陆的是最后结尾是email
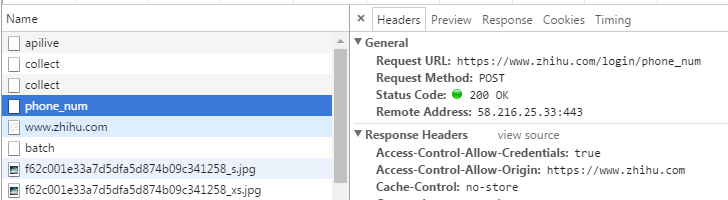
所以我们只需要向这个地址post数据就行了

phone_num 登录名
password 密码
captcha_type 验证码类型(这个参数着这里并没有实质作用)
rember_me 记住密码
_xsrf 一个隐藏的表单元素 知乎用来防御CSRF的(关于CSRF请打开这里) 我发现这个值是固定所以就在这里直接写死了 若果有兴趣的同学可以写一个正则表达式 把这部分的值提取出来 这样更严谨一些。
# -*- coding:utf-8 -*-
import urllib2
import urllib
import cookielib
posturl = 'https://www.zhihu.com/login/phone_num'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/52.0.2743.116 Safari/537.36',
'Referer':'https://www.zhihu.com/'
}
value = {
'password':'*****************',
'remember_me':True,
'phone_num':'*******************',
'_xsrf':'**********************'
}
data=urllib.urlencode(value)
#初始化一个CookieJar来处理Cookie
cookieJar=cookielib.CookieJar()
cookie_support = urllib2.HTTPCookieProcessor(cookieJar)
#实例化一个全局opener
opener=urllib2.build_opener(cookie_support)
request = urllib2.Request(posturl, data, headers)
result=opener.open(request)
print result.read()
当你看到服务器返回这个信息的时候就说明你登陆成功了
{"r":0,
"msg": "\u767b\u5f55\u6210\u529f"
}#翻译过来就是 “登陆成功” 四个大字
然后你就可以用这个身份去抓取知乎上的页面了
page=opener.open("https://www.zhihu.com/people/yu-yi-56-70")
content = page.read().decode('utf-8')
print(content)
这段代码就是通过实例化一个opener对象保存成功登陆后的cookie信息,然后再通过这个opener带着这个cookie去访问服务器上关于这个身份的完整页面。更复杂的比如微博的登陆这种对请求的数据进行加密了的后面有时间再写出来,与大家分享