yipeiwu_com6年前
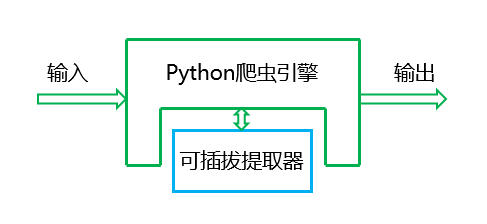
1. 项目背景 在python 即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间,从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高...
yipeiwu_com6年前
本文详细介绍了网站的反爬虫策略,在这里把我写爬虫以来遇到的各种反爬虫策略和应对的方法总结一下。 从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。这里我们只讨论数据采集部分。 一...
yipeiwu_com6年前
背景 中秋的时候,一个朋友给我发了一封邮件,说他在爬链家的时候,发现网页返回的代码都是乱码,让我帮他参谋参谋(中秋加班,真是敬业= =!),其实这个问题我很早就遇到过,之前在爬小说的时候...
yipeiwu_com6年前
前言 本文给大家介绍的是利用Python抓取手机归属地信息,文中给出了详细的示例代码,相信对大家的理解和学习很有帮助,以下为Python代码,较为简单,供参考。 示例代码 # -*-...
yipeiwu_com6年前
前言 国家统计局网站上有相对比较齐的行政区划码,对于一些网站来说这是非常基础的数据,所以写了个Python程序将这部分数据抓取下来。 注意:抓取下来以后还要进行简单的人工的整理 示例代码...
yipeiwu_com6年前
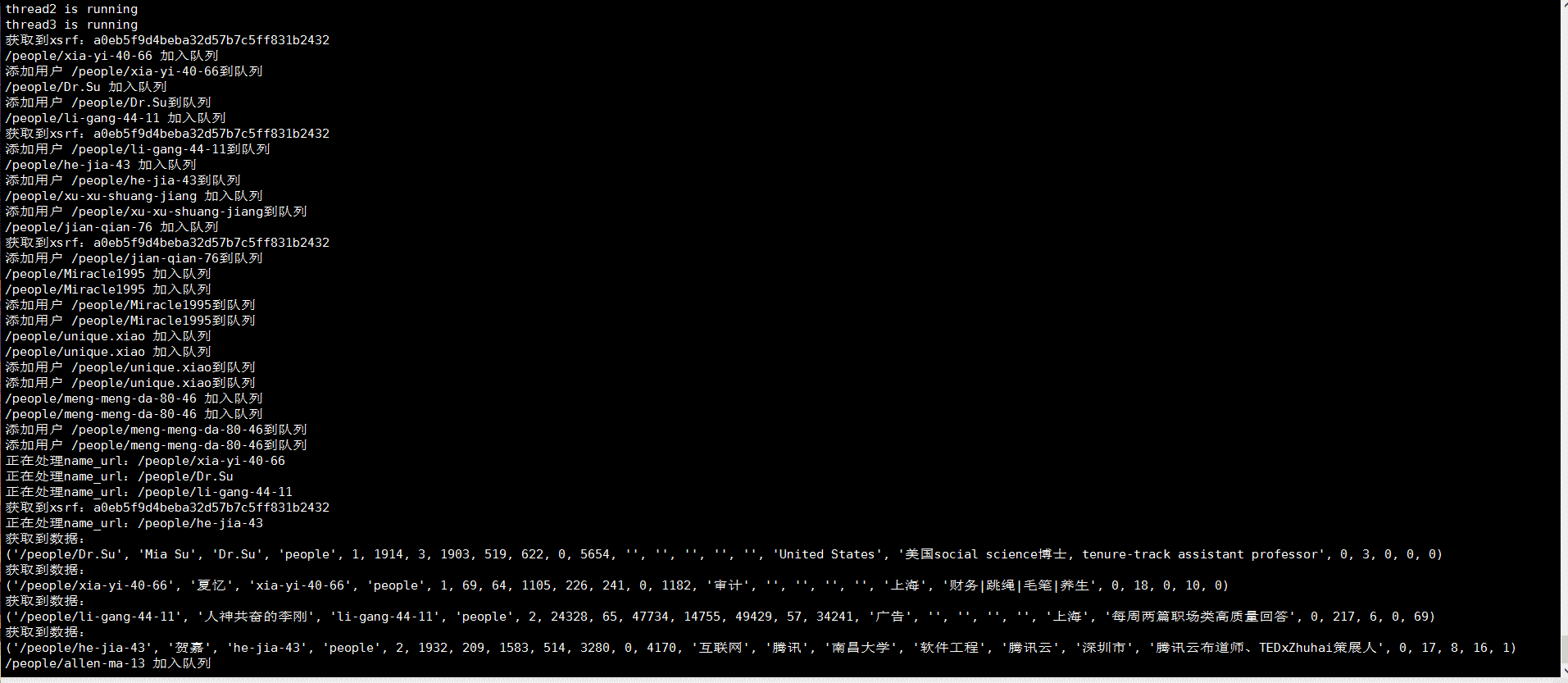
需要用到的包: beautifulsoup4 html5lib image requests redis PyMySQL pip安装所有依赖包: pip install \...
yipeiwu_com6年前
写在前面 这次的爬虫是关于房价信息的抓取,目的在于练习10万以上的数据处理及整站式抓取。 数据量的提升最直观的感觉便是对函数逻辑要求的提高,针对Python的特性,谨慎的选择数据结构。以...
yipeiwu_com6年前
写在前面 题目所说的并不是目的,主要是为了更详细的了解网站的反爬机制,如果真的想要提高博客的阅读量,优质的内容必不可少。 了解网站的反爬机制 一般网站从以下几个方面反爬虫: 1. 通过H...
yipeiwu_com6年前
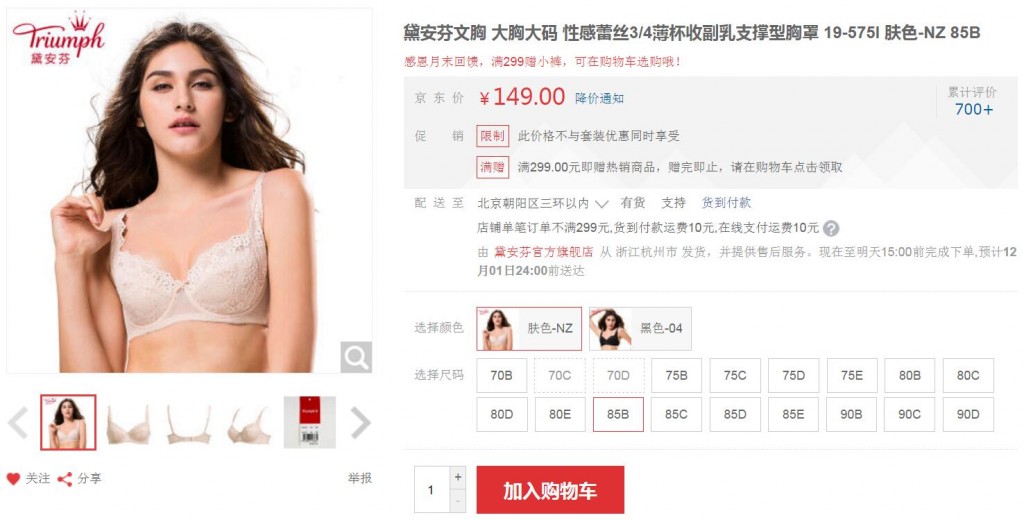
本篇文章是python爬虫系列的第三篇,介绍如何抓取京东商城商品评论信息,并对这些评论信息进行分析和可视化。下面是要抓取的商品信息,一款女士文胸。这个商品共有红色,黑色和肤色三种颜色,...
yipeiwu_com6年前
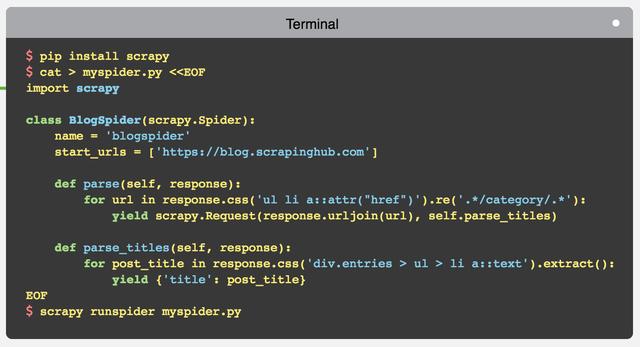
简介 scrapy 是一个 python 下面功能丰富、使用快捷方便的爬虫框架。用 scrapy 可以快速的开发一个简单的爬虫,官方给出的一个简单例子足以证明其强大: 快速开发 下面开...