yipeiwu_com6年前
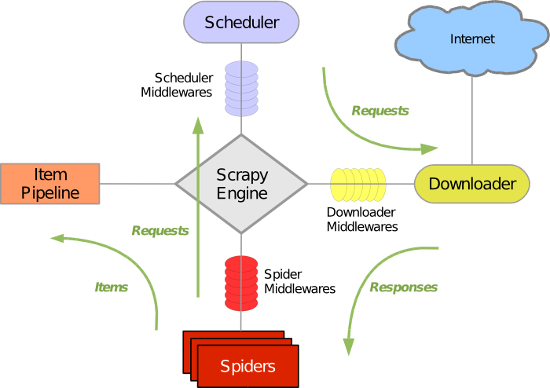
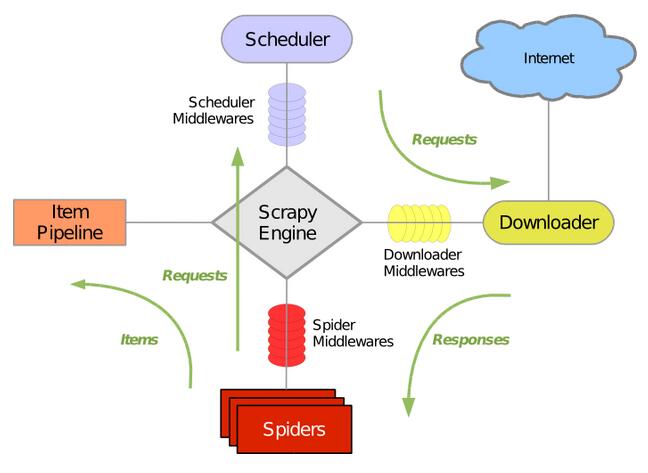
1. Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 其最初是为了页面抓取 (更...
yipeiwu_com6年前
一、Cookie原理 HTTP是无状态的面向连接的协议, 为了保持连接状态, 引入了Cookie机制 Cookie是http消息头中的一种属性,包括: Cookie名字(Name)...
yipeiwu_com6年前
前言 写过的这些脚本有一个共性,都是和web相关的,总要用到获取链接的一些方法,累积不少爬虫抓站的经验,在此总结一下,那么以后做东西也就不用重复劳动了。 1.最基本的抓站 impor...
yipeiwu_com6年前
最近在学Python,同时也在学如何使用python抓取数据,于是就被我发现了这个非常受欢迎的Python抓取框架Scrapy,下面一起学习下Scrapy的架构,便于更好的使用这个工具。...
yipeiwu_com6年前
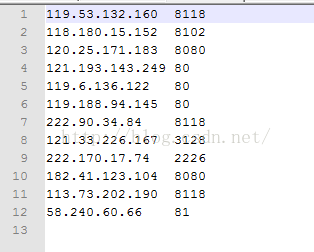
前言 就以最近发现的一个免费代理IP网站为例:http://www.xicidaili.com/nn/。在使用的时候发现很多IP都用不了。 所以用Python写了个脚本,该脚本可以把能用...
yipeiwu_com6年前
前言 关于python版本,我一开始看很多资料说python2比较好,因为很多库还不支持3,但是使用到现在为止觉得还是pythin3比较好用,因为编码什么的问题,觉得2还是没有3方便。而...
yipeiwu_com6年前
前言 本文主要的知识点是使用Python的BeautifulSoup进行多层的遍历。 如图所示。只是一个简单的哈,不是爬取里面的隐藏的东西。 示例代码 from bs4 impor...
yipeiwu_com6年前
一直有爱看美剧的习惯,一方面锻炼一下英语听力,一方面打发一下时间。之前是能在视频网站上面在线看的,可是自从广电总局的限制令之后,进口的美剧英剧等貌似就不在像以前一样同步更新了。但是,作为...
yipeiwu_com6年前
本文的爬虫教程分为四部: 1.从哪爬 where 2.爬什么 what &...
yipeiwu_com6年前
正则表达式的使用 想要学习 Python 爬虫 , 首先需要了解一下正则表达式的使用,下面我们就来看看如何使用。 . 的使用这个时候的点就相当于一个占位符,可以匹配任意一个字符,什么意思...