yipeiwu_com6年前
在这篇文章中,我们将分析一个网络爬虫。 网络爬虫是一个扫描网络内容并记录其有用信息的工具。它能打开一大堆网页,分析每个页面的内容以便寻找所有感兴趣的数据,并将这些数据存储在一个数据库中,...
yipeiwu_com6年前
操作:输入带分页的地址,去掉最后面的数字,设置一下起始页数和终点页数 功能:下载对应页码的所有页面并储存为HTML文件,以当前时间命名 代码: # -*- coding: utf-8...
yipeiwu_com6年前
web数据抓取是一个经常在python的讨论中出现的主题。有很多方法可以用来进行web数据抓取,然而其中好像并没有一个最好的办法。有一些如scrapy这样十分成熟的框架,更多的则是像me...
yipeiwu_com6年前
本文实例讲述了Python使用scrapy抓取网站sitemap信息的方法。分享给大家供大家参考。具体如下: import re from scrapy.spider import...
yipeiwu_com6年前
本文实例讲述了Python打印scrapy蜘蛛抓取树结构的方法。分享给大家供大家参考。具体如下: 通过下面这段代码可以一目了然的知道scrapy的抓取页面结构,调用也非常简单 #!/...
yipeiwu_com6年前
使用ghost.py 通过搜搜 的微信搜索来爬取微信公共账号的信息 # -*- coding: utf-8 -*- import sys reload(sys) import dat...
yipeiwu_com6年前
本文实例讲述了python使用自定义user-agent抓取网页的方法。分享给大家供大家参考。具体如下: 下面python代码通过urllib2抓取指定的url的内容,并且使用自定义的u...
yipeiwu_com6年前
在这个教材中,我们假定你已经安装了Scrapy。假如你没有安装,你可以参考这个安装指南。 我们将会用开放目录项目(dmoz)作为我们例子去抓取。 这个教材将会带你走过下面这几...
yipeiwu_com6年前
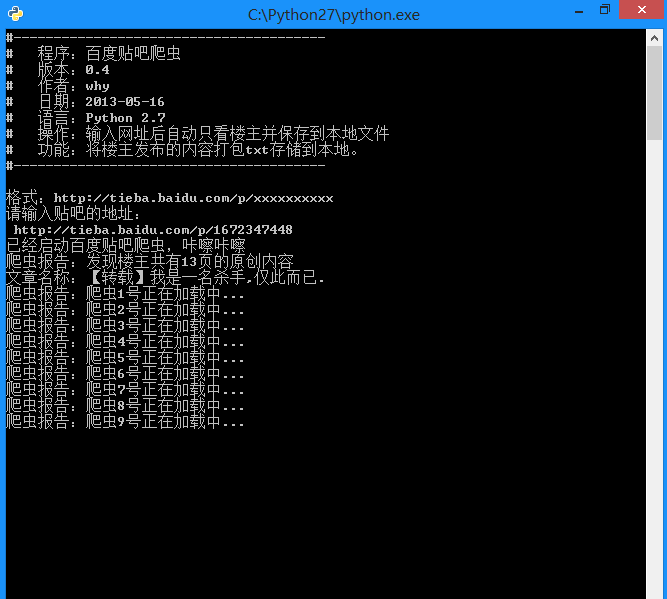
本文实例讲述了基于Python实现的百度贴吧网络爬虫。分享给大家供大家参考。具体如下: 完整实例代码点击此处本站下载。 项目内容: 用Python写的百度贴吧的网络爬虫。 使用方法: 新...
yipeiwu_com6年前
刚才好无聊,突然想起来之前做一个课表的点子,于是百度了起来。 刚开始,我是这样想的:在写微信墙的时候,用到了urllib2【两行代码抓网页】,那么就只剩下解析html了。于是百度:pyt...