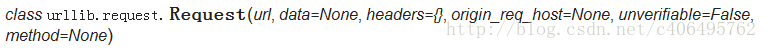Python编写百度贴吧的简单爬虫
操作:输入带分页的地址,去掉最后面的数字,设置一下起始页数和终点页数
功能:下载对应页码的所有页面并储存为HTML文件,以当前时间命名
代码:
# -*- coding: utf-8 -*-
#----------------------------
# 程序:百度贴吧的小爬虫
# 日期:2015/03/28
# 语言:Python 2.7
# 操作:输入带分页的地址,去掉最后面的数字,设置一下起始页数和终点页数
# 功能:下载对应页码的所有页面并储存为HTML文件,以当前时间命名
#----------------------------
import urllib2
import time
def baidu_tieba(url, start, end):
for i in range(start, end):
sName = time.strftime('%Y%m%d%H%M%S') + str(i) + '.html'
print '正在下载第' + str(i) + '个网页,并将其储存为' + sName + '...'
f = open(sName, 'w+')
m = urllib2.urlopen(url+str(i))
n = m.read()
f.write(n)
f.close()
print '成功下载'
baiduurl = str(raw_input('请输入贴子的地址,去掉pn后面的数字>>\n'))
begin_page = int(raw_input('请输入帖子的起始页码>>\n'))
end_page = int(raw_input('请输入帖子的终止页码>>\n'))
baidu_tieba(baiduurl, begin_page, end_page)
以上所述就是本文的全部内容了,希望能够对大家学习Python制作爬虫有所帮助。