在Python中使用cookielib和urllib2配合PyQuery抓取网页信息
刚才好无聊,突然想起来之前做一个课表的点子,于是百度了起来。
刚开始,我是这样想的:在写微信墙的时候,用到了urllib2【两行代码抓网页】,那么就只剩下解析html了。于是百度:python解析html。发现一篇好文章,其中介绍到了pyQuery。
pyQuery 是 jQuery 在 Python 中的实现,能够以 jQuery 的语法來操作解析 HTML 文档。使用前需要安装,Mac安装方法如下:
sudo easy_install pyquery
OK!安装好了!
我们来试一试吧:
from pyquery import PyQuery as pq
html = pq(url=u'http://seam.ustb.edu.cn:8080/jwgl/index.jsp')
#现在已经获取了本科教学网首页的html
classes = html('.haveclass')
#通过类名获取元素
#如果你对jQuery熟悉的话,那么你现在肯定明白pyQuery的方便了
更多用法参见pyQuery API
好像学会了使用pyQuery就能抓课表了呢,但是,如果你直接用我的源码,肯定会出错。因为还没有登录啊!
所以,在运行这一行抓取正确的代码之前,我们需要模拟登录本科教学网。这个时候,我想起来urllib有模拟post请求的函数,于是我百度了:urllib post。
这是一个最简的模拟post请求例子:
import urllib
import urllib2
import cookielib
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)')]
urllib2.install_opener(opener)
req = urllib2.Request("http://seam.ustb.edu.cn:8080/jwgl/Login",urllib.urlencode({"username":"41255029","password":"123456","usertype":"student"}))
req.add_header("Referer","http://xxoo.com")
resp = urllib2.urlopen(req)
#这里面用到了cookielib,我不太清楚,以后慢慢了解吧
#还用到了urllib和urllib2,urllib2大概是urllib的扩展包【233想到了三国杀
在这个最简的实例里,用我的校园网账号向登录页面提交表单数据,模拟登录。
现在,我们已经登录了本科教学网,然后结合之前的pyQuery解析html就可以获取网页内的课表了。
html = pq(url=u'http://seam.ustb.edu.cn:8080/jwgl/index.jsp')
self.render("index.html",data=html('.haveclass'))
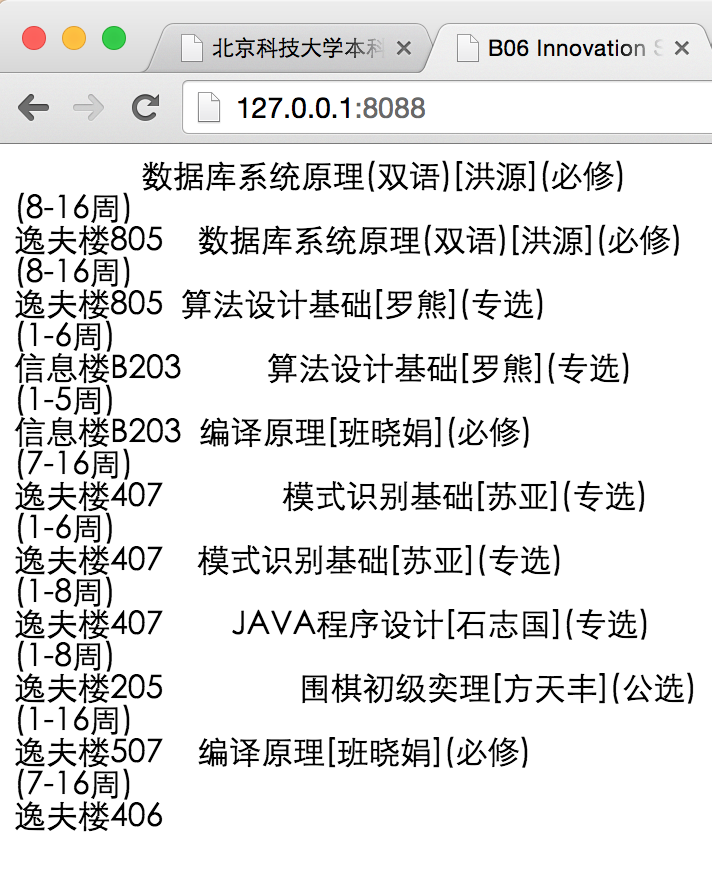
结果展示如图:
最后:
我发现,pyQuery不但用于解析html非常方便,而且可以作为跨域抓取数据的工具,NICE!!!
希望对大家有帮助。