yipeiwu_com6年前
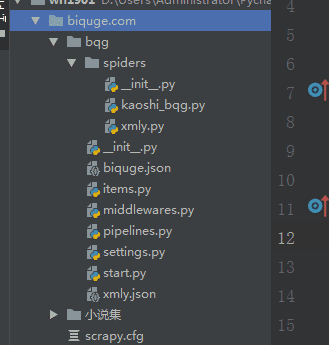
涉及到详情页爬取 目录结构: kaoshi_bqg.py import scrapy from scrapy.spiders import Rule from scrapy.lin...
yipeiwu_com6年前
导入相关包 import time import pydash import base64 import requests from lxml import etree from...
yipeiwu_com6年前
简介 提到爬虫,大部分人都会想到使用Scrapy工具,但是仅仅停留在会使用的阶段。为了增加对爬虫机制的理解,我们可以手动实现多线程的爬虫过程,同时,引入IP代理池进行基本的反爬操作。...
yipeiwu_com6年前
一:脚本需求 利用Python3查询网站权重并自动存储在本地数据库(Mysql数据库)中,同时导出一份网站权重查询结果的EXCEL表格 数据库类型:MySql 数据库表单名称:webs...
yipeiwu_com6年前
进入智联招聘官网,在搜索界面输入‘数据分析师',界面跳转,按F12查看网页源码,点击network 选中XHR,然后刷新网页 可以看到一些Ajax请求, 找到画红线的XH...
yipeiwu_com6年前
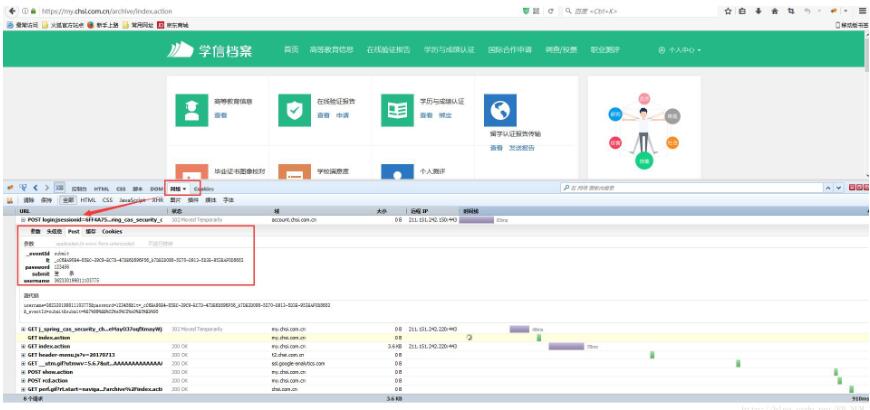
我们以学信网为例爬取个人信息 **如果看不清楚 按照以下步骤:** 1.火狐为例 打开需要登录的网页–> F12 开发者模式 (鼠标右击,点击检查元素)–点击网络 –>需要...
yipeiwu_com6年前
目的:爬取阳光热线问政平台问题反映每个帖子里面的标题、内容、编号和帖子url CrawlSpider版流程如下: 创建爬虫项目dongguang scrapy startproje...
yipeiwu_com6年前
目的:获取腾讯社招这个页面的职位名称及超链接 职位类别 人数 地点和发布时间 要求:使用bs4进行解析,并把结果以json文件形式存储 注意:如果直接把python列表没有序列化为jso...
yipeiwu_com6年前
目的:在百度贴吧输入关键字和要查找的起始结束页,获取帖子里面楼主所发的图片 思路: 获取分页里面的帖子链接列表 获取帖子里面楼主所发的图片链接列表 保存图片到本地 注意事...
yipeiwu_com6年前
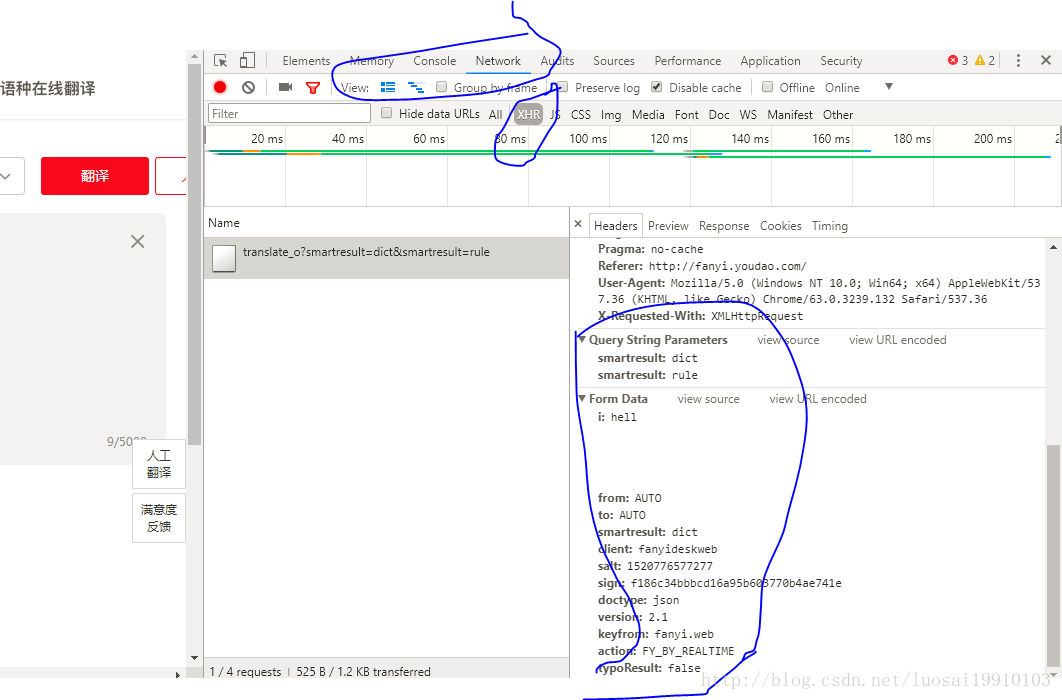
前言 最近在学习python 爬虫方面的知识,网上有一博客专栏专门写爬虫方面的,看到用urllib请求有道翻译接口获取翻译结果。发现接口变化很大,用md5加了密,于是自己开始破解。加上...