Python爬取智联招聘数据分析师岗位相关信息的方法
进入智联招聘官网,在搜索界面输入‘数据分析师',界面跳转,按F12查看网页源码,点击network

选中XHR,然后刷新网页

可以看到一些Ajax请求, 找到画红线的XHR文件,点击可以看到网页的一些信息
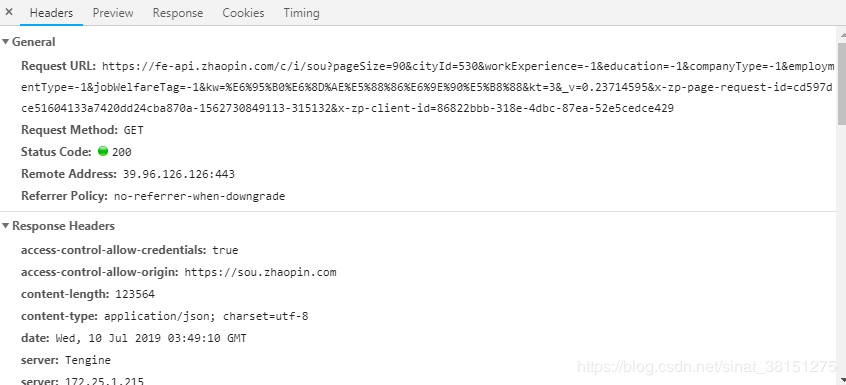

在Header中有Request URL,我们需要通过找寻Request URL的特点来构造这个请求网址,
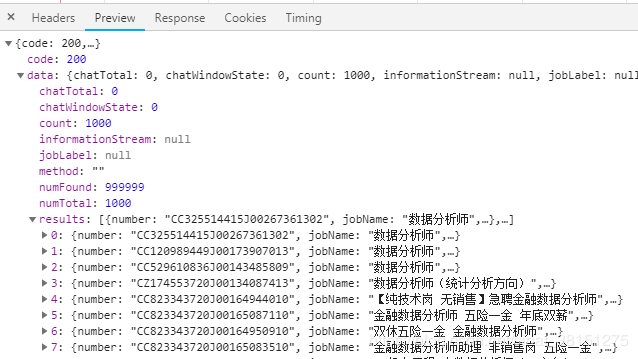
点击Preview,可以看到我们所需要的信息就存在result中,这信息基本是json格式,有些是列表;
下面我们通过Python爬虫来爬取上面的信息;
代码如下:
import requests
from urllib.parse import urlencode
import json
#from requests import codes
#import os
#from hashlib import md5
#from multiprocessing.pool import Pool
#import re
def get_page(offset):
params = {
'start': offset,
'pageSize': '90',
'cityId': '530',
'salary': '0,0',
'workExperience': '-1',
'education': '-1',
'companyType': '-1',
'employmentType': '-1',
'jobWelfareTag': '-1',
'kw': '数据分析师',
'kt': '3',
'_v': '0.77091902',
'x-zp-page-request-id': '8ff0aa73bf834b408f46324e44d89b84-1562722989022-210101',
'x-zp-client-id': '2dc4c9a4-e80d-4488-84a3-03426dd69a1e'
}
base_url = 'https://fe-api.zhaopin.com/c/i/sou?'
url = base_url + urlencode(params)
try:
resp = requests.get(url)
print(url)
if 200 == resp.status_code:
print(resp.json())
return resp.json()
except requests.ConnectionError:
return None
def get_information(json_page):
if json_page.get('data'):
results = json_page.get('data').get('results')
for result in results:
yield {
'city': result.get('city').get('display'),
'company': result.get('company').get('name'),
#'welfare':result.get('welfare'),
'workingExp':result.get('workingExp').get('name'),
'salary':result.get('salary'),
'eduLevel':result.get('eduLevel').get('name')
}
print('succ')
def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
print(type(json.dumps(content)))
f.write(json.dumps(content,ensure_ascii=False)+'\n')
def main(offset):
json_page=get_page(offset)
for content in get_information(json_page):
write_to_file(content)
if __name__=='__main__':
for i in range(10):
main(offset=90*i)
爬取结果如下:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。