python 爬取学信网登录页面的例子
我们以学信网为例爬取个人信息
**如果看不清楚
按照以下步骤:**
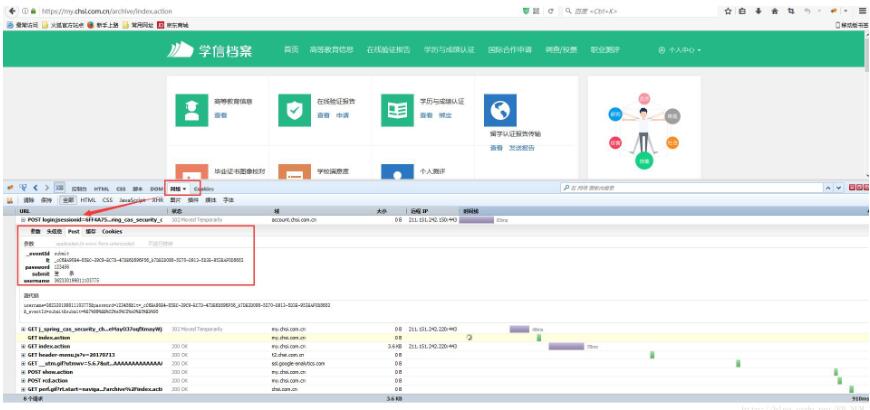
1.火狐为例 打开需要登录的网页–> F12 开发者模式 (鼠标右击,点击检查元素)–点击网络 –>需要登录的页面登录下–> 点击网络找到 一个POST提交的链接点击–>找到post(注意该post中信息就是我们提交时需要构造的表单信息)
import requests
from bs4 import BeautifulSoup
from http import cookies
import urllib
import http.cookiejar
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0',
'Referer':'https://account.chsi.com.cn/passport/login?service=https://my.chsi.com.cn/archive/j_spring_cas_security_check',
}
session = requests.Session()
session.headers.update(headers)
username = 'xxx'
password = 'xxx'
url = 'https://account.chsi.com.cn/passport/login?service=https://my.chsi.com.cn/archive/j_spring_cas_security_check'
def login(username,password,lt,_eventId='submit'): #模拟登入函数
#构造表单数据
data = { #需要传去的数据
'_eventId':_eventId,
'lt':lt,
'password':password,
'submit':u'登录',
'username':username,
}
html = session.post(url,data=data,headers=headers)
def get_lt(url): #解析登入界面_eventId
html = session.get(url)
#获取 lt
soup = BeautifulSoup(html.text,'lxml',from_encoding="utf-8")
lt=soup.find('input',type="hidden")['value']
return lt
lt = get_lt(url)#获取登录form表单信息 以学信网为例
login(username,password,lt)
login_url = 'https://my.chsi.com.cn/archive/gdjy/xj/show.action'
per_html = session.get(login_url)
soup = BeautifulSoup(per_html.text,'lxml',from_encoding="utf-8")
print(soup)
for tag in soup.find_all('table',class_='mb-table'):
print(tag)
for tag1 in tag.find_all('td'):
title= tag1.get_text();
print(title)
以上这篇python 爬取学信网登录页面的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。