yipeiwu_com6年前
beautifulsoup解析页面 from bs4 import BeautifulSoup soup = BeautifulSoup(htmltxt, "lxml") # 三种装...
yipeiwu_com6年前
摘要 如何用beautifulsoup4解析各种情况的网页 beautifulsoup4的使用 关于beautifulsoup4,官网已经讲的很详细了,我这里就把一些常用的解析方...
yipeiwu_com6年前
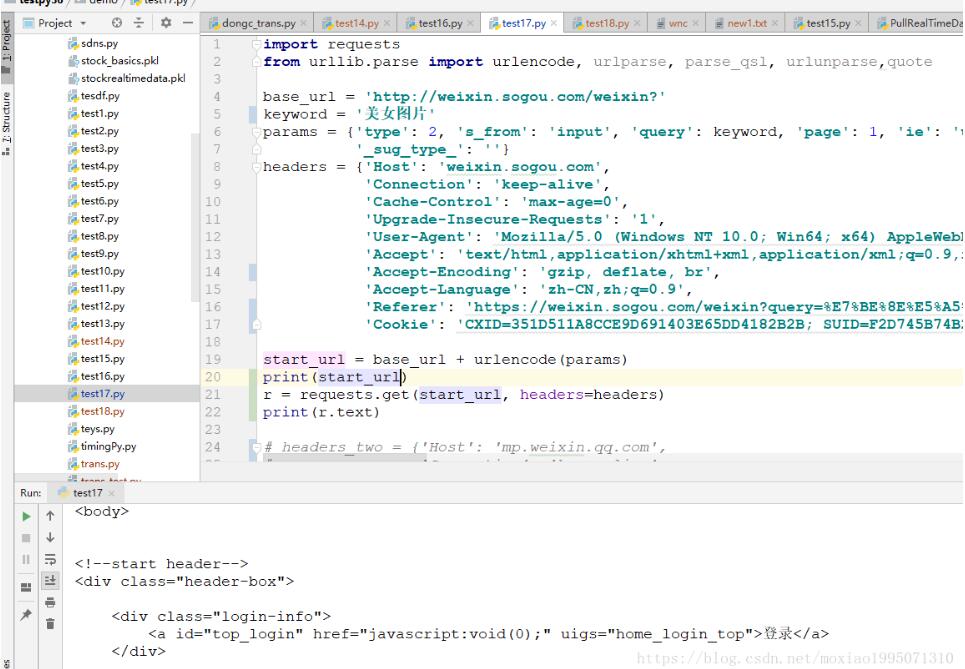
最近在学习Python3网络爬虫开发实践(崔庆才 著)刚好也学习到他使用代理爬取公众号文章这里,但是照着他的代码写,出现了一些问题。在这里我用到了这本书的前面讲的一些内容进行了完善。(作...
yipeiwu_com6年前
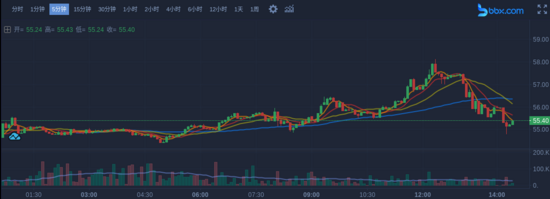
一、前言 作为一名爬虫工程师,在工作中常常会遇到爬取实时数据的需求,比如体育赛事实时数据、股市实时数据或币圈实时变化的数据。如下图: Web 领域中,用于实现数据'实时'更新的手段...
yipeiwu_com6年前
安装 安装很简单,只要执行: pip install requests-html 就可以了。 分析页面结构 通过浏览器审查元素可以发现这个电子书网站是用 WordPress 搭建的...
yipeiwu_com6年前
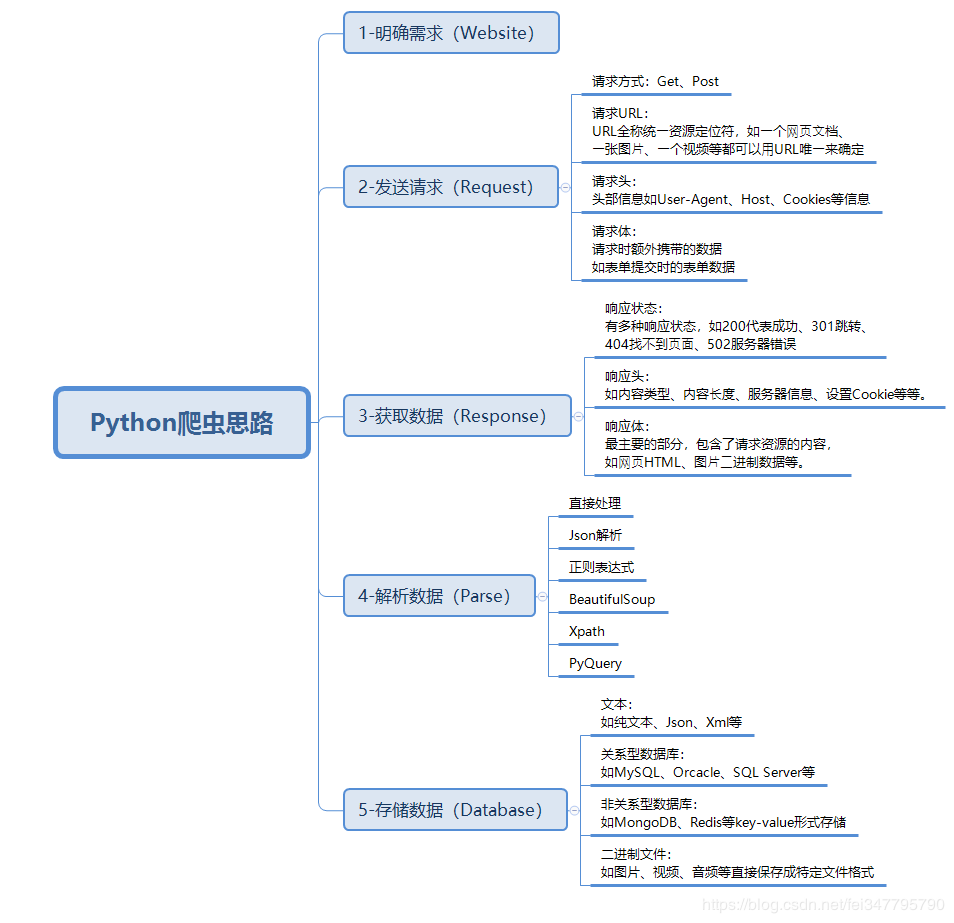
什么是爬虫? 网络爬虫也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,爬虫程序通过请求url地址,根据响应的内容进行解析采集数据, 比如:如果响应内容是ht...
yipeiwu_com6年前
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员。 在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息。 数据格式:{"nam...
yipeiwu_com6年前
目标网站: 首先获取第一页的数据,这里关键要切换到iframe里 打印一下 获取剩下的页数,这里在点击下一页之前需要设置一个延迟,不然会报错。 结果: 一共37页,爬取完...
yipeiwu_com6年前
一、乱码问题描述 经常在爬虫或者一些操作的时候,经常会出现中文乱码等问题,如下 原因是源网页编码和爬取下来后的编码格式不一致 二、利用encode与decode解决乱码问题...
yipeiwu_com6年前
本文实例讲述了Python实现的爬取小说爬虫功能。分享给大家供大家参考,具体如下: 想把顶点小说网上的一篇持续更新的小说下下来,就写了一个简单的爬虫,可以爬取爬取各个章节的内容,保存到t...