yipeiwu_com6年前
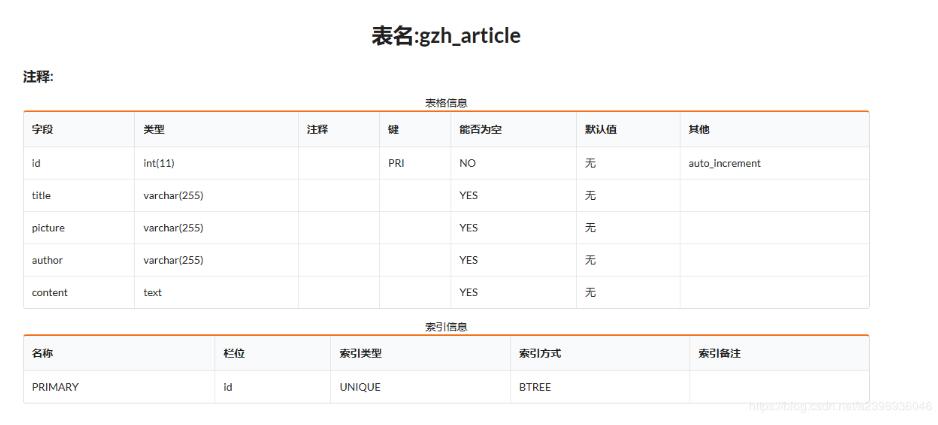
初学python,抓取搜狗微信公众号文章存入mysql mysql表: 代码: import requests import json import re import pymy...
yipeiwu_com6年前
requests是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到。可以说,Requests 完全满足如今网络的需求。本文重点给大家介绍python使...
yipeiwu_com6年前
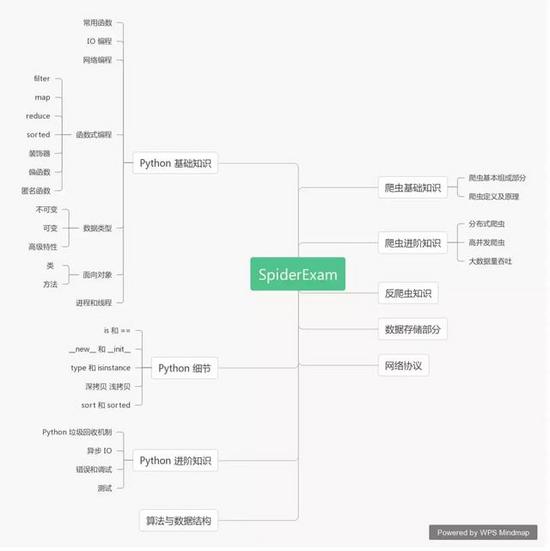
先来一份完整的爬虫工程师面试考点: 一、 Python 基本功 1、简述Python 的特点和优点 Python 是一门开源的解释性语言,相比 Java C++ 等语言,Python...
yipeiwu_com6年前
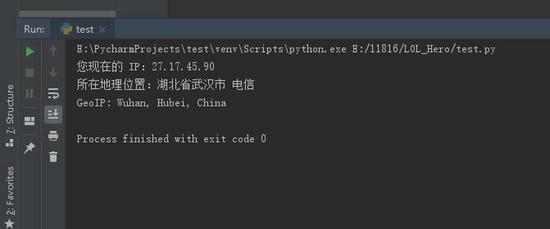
在使用python对网页进行多次快速爬取的时候,访问次数过于频繁,服务器不会考虑User-Agent的信息,会直接把你视为爬虫,从而过滤掉,拒绝你的访问,在这种时候就需要设置代理,我们可...
yipeiwu_com6年前
本文实例讲述了Python爬虫实现爬取百度百科词条功能。分享给大家供大家参考,具体如下: 爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。爬虫从一个或...
yipeiwu_com6年前
本文实例讲述了Python HTML解析模块HTMLParser用法。分享给大家供大家参考,具体如下: 简介 先简略介绍一下。实际上,HTMLParser是python用来解析HTML的...
yipeiwu_com6年前
本文实例讲述了Python HTML解析器BeautifulSoup用法。分享给大家供大家参考,具体如下: BeautifulSoup简介 我们知道,Python拥有出色的内置HTML解...
yipeiwu_com6年前
前言 我们这里主要是利用requests模块和bs4模块进行简单的爬虫的讲解,让大家可以对爬虫有了初步的认识,我们通过爬几个简单网站,让大家循序渐进的掌握爬虫的基础知识,做网络爬虫还是需...
yipeiwu_com6年前
python爬取数据保存为Json格式 代码如下: #encoding:'utf-8' import urllib.request from bs4 import Beautiful...
yipeiwu_com6年前
get请求 简单使用 import requests ''' 想要学习Python?Python学习交流群:973783996满足你的需求,资料都已经上传群文件,可以自行下载! ''...