详解Python解决抓取内容乱码问题(decode和encode解码)
一、乱码问题描述
经常在爬虫或者一些操作的时候,经常会出现中文乱码等问题,如下
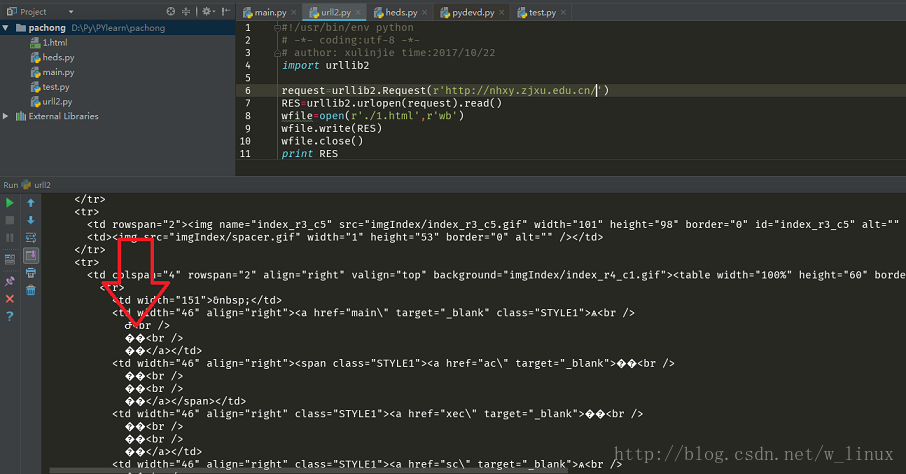
原因是源网页编码和爬取下来后的编码格式不一致
二、利用encode与decode解决乱码问题
字符串在Python内部的表示是unicode编码,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode(‘utf-8'),表示将unicode编码的字符串str2转换成utf-8编码。
decode中写的就是想抓取的网页的编码,encode即自己想设置的编码
代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
或者
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
但是还要注意:
如果一个字符串已经是unicode了,再进行解码则将出错,因此通常要对其编码方式是否为unicode进行判断
isinstance(s, unicode)#用来判断是否为unicode
用非unicode编码形式的str来encode会报错
所以最终可靠代码:
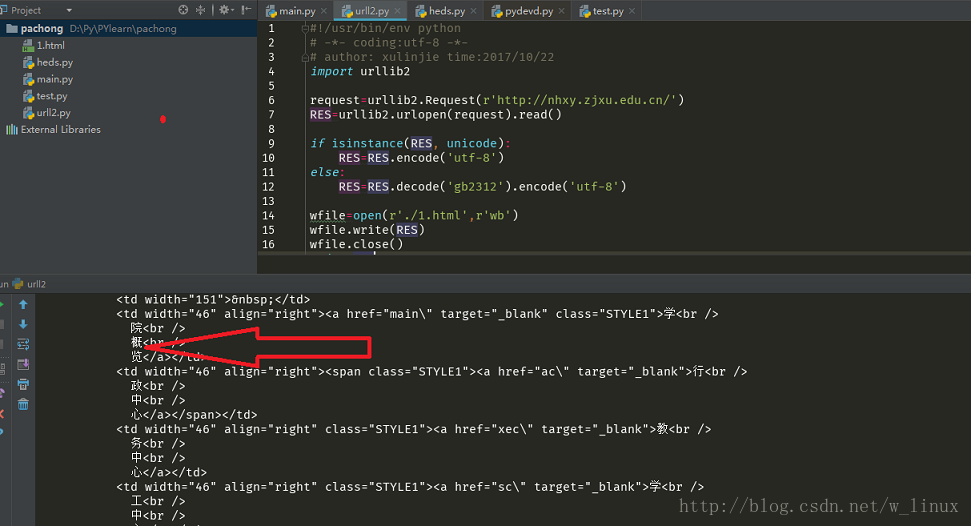
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
if isinstance(RES, unicode):
RES=RES.encode('utf-8')
else:
RES=RES.decode('gb2312').encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
三、如何找到需要抓取的目标网页的编码格式
1、查看网页源代码

如果源代码中没有charset编码格式显示可以用下面的方法
2、检查元素,查看Response Headers

以上所述是小编给大家介绍的Python解决抓取内容乱码问题(decode和encode解码)详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!