windows7 32、64位下python爬虫框架scrapy环境的搭建方法
适用于python 2.7 64位安装
一、操作系统:WIN7 64位
二、python版本:2.7 64位(scrapy目前不支持3.x)
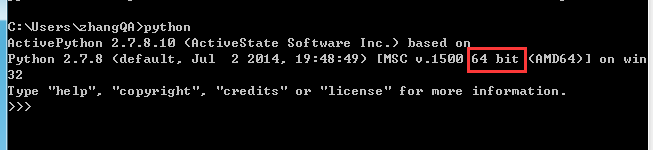
不确定位数的,看图
三、安装相关软件(可以从我的百度网盘下载:链接: https://pan.baidu.com/s/1MzHNALJcRePSoaEqBQvGAQ 提取码: xd5e )
我配置环境的时候是直接pip install scrapy安装的,但是在过程中出现一些错误,发现是由于以下软件安装失败导致的。所以请先安装这4个相关软件再安装scrapy。
一定要注意看看,你的python是不是64位的,位数一样才可以哈。否则要报错滴。
- pywin32-218.win-amd64-py2.7.exe 下载网站: https://sourceforge.net/projects/pywin32/files/pywin32/
- pyOpenSSL-0.13.1.win-amd64-py2.7.exe 官方主页:http://pypi.python.org/pypi/pyOpenSSL
- lxml-3.6.4-cp27-cp27m-win_amd64.whl 下载网站: http://www.lfd.uci.edu/~gohlke/pythonlibs/
- VCForPython27.msi
安装验证:cmd进入python控制中心,注意大小写敏感
import win32com import OpenSSL import lxml
如果没有报错,证明安装成功
四、安装scrapy:
使用pip命令
pip install scrapy
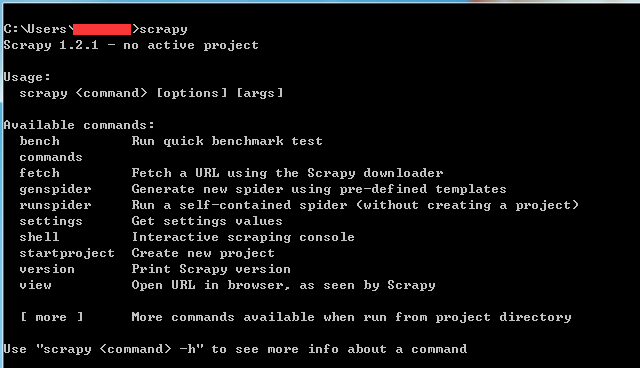
验证安装:cmd输入scrapy
scrapy
如果没有报错,如下图。证明安装成功
32位win7的安装过程和上述类似,只是文件不同。